




スケールと感度のバランス: 大規模な人間参加型 AI 評価の課題
急速に進歩する人工知能 (AI) の分野では、人間参加型 (HITL) 評価が人間の感性と機械の効率の間の重要な架け橋として機能します。ただし、

AI 評価のための効果的な人間参加型システムの設計
はじめに 人間の直感と監視を AI モデル評価に統合することは、ヒューマンインザループ (HITL) システムとして知られており、より多くのことを追求するためのフロンティアを表します。

生成 AI による医療の強化: 診断と治療に革命を起こす
近年、人工知能(AI)はさまざまな業界で大きな進歩を遂げており、ヘルスケアも例外ではありません。生成 AI、AI に焦点を当てたサブセット
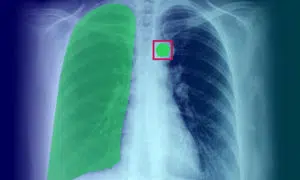
医用画像アノテーション: 定義、アプリケーション、ユースケース、タイプ
医療画像のアノテーションは、機械学習アルゴリズムと AI モデルに必要なトレーニング データを提供する上で重要な役割を果たします。このプロセスは、

倫理と偏見: モデル評価における人間と AI のコラボレーションの課題を乗り越える
人工知能 (AI) の変革力を活用する中で、テクノロジー コミュニティは、倫理的整合性の確保と偏見の最小限化という重大な課題に直面しています。

人間味: 主観的な評価で AI の創造性を高める
急速に進化する人工知能 (AI) の世界では、創造性の探求はもはや人間だけの努力ではありません。今日の AI テクノロジーは破壊されつつあります

データのラベル付けによる検索の関連性の最大化: ヒントとベスト プラクティス
今日のユーザーは膨大な量の情報に浸かっているため、必要な情報を見つけるのが複雑になっています。 検索の関連性は情報の正確さを測定します。

ギャップを埋める: 人間の直感を AI モデルの評価に統合する
はじめに 人工知能 (AI) が私たちの生活のあらゆる側面を形作る時代において、人間の直感を AI モデルの評価に統合することが次のように浮上します。

機械学習プロジェクトに最適なオープンソースのヘルスケア データセット
世界的な医療システムでは毎日膨大な量の医療データが生成されており、機械学習アプリケーションに利用される可能性があります。

AI におけるデータ プライバシーのナビゲート: コンプライアンスとイノベーションの戦略
はじめに 人工知能 (AI) の急速に進化する状況において、OpenAI のような企業は、データに対する飽くなきニーズと厳しい要求とのバランスをとるという重大な課題に直面しています。
インテリジェント文字認識 (ICR) によるデータの未来
デジタルの世界でも手書きのメモには特別な魅力があります。インテリジェント文字認識 (ICR) はアナログとデジタルの溝を埋めるのに役立ち、手書きのテキストを変換します

NLP が医療診断に及ぼす影響
自然言語処理 (NLP) は、テクノロジーとの対話方法を変革します。人間の言語を処理して、膨大な情報の可能性を解き放ちます。このテクノロジーには同じ可能性が秘められています

AI モデルに適した音声認識データセットの選択
Siri または Alexa と対話することを想像してください。私たちの言葉を理解する彼らの能力は興味深いものです。この機能は、トレーニングで使用されるデータセットに由来します。これら

ヘルスケア データセット: ヘルスケア AI の恩恵
人工知能は、かつては主に SF の世界で使われていた用語ですが、現在では現実となり、さまざまな産業の成長を促進しています。次の一手戦略コンサルティング


AI 幻覚の原因 (およびそれを軽減するテクニック)
AI 幻覚とは、AI モデル、特に大規模言語モデル (LLM) が、真実であるように見えるが、不正確であるか、現実とは無関係な情報を生成するインスタンスを指します。

臨床検証とは何ですか?ベストプラクティスとプロセスのガイド
新しい診断ツールが開発されるシナリオを考えてみましょう。医師たちはその可能性に興奮しています。しかし、それを日常のケアに組み込む前に、

倫理的AI/公正なAIの重要性と回避すべきバイアスの種類
人工知能 (AI) の急成長分野では、倫理的配慮と公平性に重点を置くことは、道徳的義務を超えたものであり、社会の基本的な必要性です。

AI 医療記録の要約: 定義、課題、ベスト プラクティス
ヘルスケア業界における医療記録の増加は、課題であると同時にチャンスでもあります。あらゆる細部が調和する世界を想像してみてください。

臨床データの抽象化: 定義、プロセスなど
病院や診療所では毎年何千人もの患者が来院します。そのためには膨大な数の専任の医師と看護師が必要です。彼らはケアを提供するために精力的に働いています

医療における合成データ: 定義、利点、および課題
研究者が新薬を開発しているシナリオを想像してみてください。検査には広範な患者データが必要ですが、プライバシーとプライバシーに関する重大な懸念があります。

匿名化に関する HIPAA 専門家の決定
医療保険の相互運用性と責任に関する法律 (HIPAA) は、医療における患者データの保護の基準を定めています。この重要な側面は、Protected の匿名化です。

NLP による先駆的な腫瘍学研究: Shaip の画期的な進歩
ケーススタディをダウンロード がんを克服するという探求においては、データは決意と同じくらい重要です。 Shaip では、大きな飛躍を可能にしたことを誇りに思っています
放射線科における自然言語処理 (NLP) の力: 診断と効率の向上
放射線医学は医療において重要な役割を果たしています。 CTスキャン、X線、MRIなどの画像技術を使用して、さまざまな状態を診断および治療します。 自然言語

腫瘍学における自然言語処理 (NLP) の役割
がんは世界的に重大な健康上の課題を引き起こしています。 これは、細胞が制御されずに増殖および拡散するときに発生します。 死因の第XNUMX位です

人間のフィードバックからの強化学習について知っておくべきことすべて
2023 年には、ChatGPT などの AI ツールの導入が大幅に増加しました。 この急増により活発な議論が始まり、人々は AI の利点について議論しています。

自動車業界における AI の力
AI を自動車に統合することに関して、世界は顕著な岐路に立たされています。 AI が交通量の多い道路を運転し、自分の車の状態を管理しているところを想像してみてください。

業界全体にわたるテキスト読み上げの利点
Text-to-speech (TTS) テクノロジーは、書かれたテキストを話し言葉に変換する革新的なソリューションです。 いくつかの業界でゲームチェンジャーとなり、革命を起こしました


データ匿名化ガイド: 初心者が知っておくべきことすべて (2024 年)
デジタル変革の時代において、医療機関は業務をデジタル プラットフォームに急速に移行しています。 これによりプロセスの効率化と合理化がもたらされますが、



















スケールと感度のバランス: 大規模な人間参加型 AI 評価の課題
急速に進歩する人工知能 (AI) の分野では、人間参加型 (HITL) 評価が人間の感性と機械の効率の間の重要な架け橋として機能します。ただし、
AI 評価のための効果的な人間参加型システムの設計
はじめに 人間の直感と監視を AI モデル評価に統合することは、ヒューマンインザループ (HITL) システムとして知られており、より多くのことを追求するためのフロンティアを表します。
生成 AI による医療の強化: 診断と治療に革命を起こす
近年、人工知能(AI)はさまざまな業界で大きな進歩を遂げており、ヘルスケアも例外ではありません。生成 AI、AI に焦点を当てたサブセット
医用画像アノテーション: 定義、アプリケーション、ユースケース、タイプ
医療画像のアノテーションは、機械学習アルゴリズムと AI モデルに必要なトレーニング データを提供する上で重要な役割を果たします。このプロセスは、
倫理と偏見: モデル評価における人間と AI のコラボレーションの課題を乗り越える
人工知能 (AI) の変革力を活用する中で、テクノロジー コミュニティは、倫理的整合性の確保と偏見の最小限化という重大な課題に直面しています。
人間味: 主観的な評価で AI の創造性を高める
急速に進化する人工知能 (AI) の世界では、創造性の探求はもはや人間だけの努力ではありません。今日の AI テクノロジーは破壊されつつあります
データのラベル付けによる検索の関連性の最大化: ヒントとベスト プラクティス
今日のユーザーは膨大な量の情報に浸かっているため、必要な情報を見つけるのが複雑になっています。 検索の関連性は情報の正確さを測定します。
ギャップを埋める: 人間の直感を AI モデルの評価に統合する
はじめに 人工知能 (AI) が私たちの生活のあらゆる側面を形作る時代において、人間の直感を AI モデルの評価に統合することが次のように浮上します。
機械学習プロジェクトに最適なオープンソースのヘルスケア データセット
世界的な医療システムでは毎日膨大な量の医療データが生成されており、機械学習アプリケーションに利用される可能性があります。
AI におけるデータ プライバシーのナビゲート: コンプライアンスとイノベーションの戦略
はじめに 人工知能 (AI) の急速に進化する状況において、OpenAI のような企業は、データに対する飽くなきニーズと厳しい要求とのバランスをとるという重大な課題に直面しています。
インテリジェント文字認識 (ICR) によるデータの未来
デジタルの世界でも手書きのメモには特別な魅力があります。インテリジェント文字認識 (ICR) はアナログとデジタルの溝を埋めるのに役立ち、手書きのテキストを変換します
NLP が医療診断に及ぼす影響
自然言語処理 (NLP) は、テクノロジーとの対話方法を変革します。人間の言語を処理して、膨大な情報の可能性を解き放ちます。このテクノロジーには同じ可能性が秘められています
AI モデルに適した音声認識データセットの選択
Siri または Alexa と対話することを想像してください。私たちの言葉を理解する彼らの能力は興味深いものです。この機能は、トレーニングで使用されるデータセットに由来します。これら
ヘルスケア データセット: ヘルスケア AI の恩恵
人工知能は、かつては主に SF の世界で使われていた用語ですが、現在では現実となり、さまざまな産業の成長を促進しています。次の一手戦略コンサルティング
AI 幻覚の原因 (およびそれを軽減するテクニック)
AI 幻覚とは、AI モデル、特に大規模言語モデル (LLM) が、真実であるように見えるが、不正確であるか、現実とは無関係な情報を生成するインスタンスを指します。
臨床検証とは何ですか?ベストプラクティスとプロセスのガイド
新しい診断ツールが開発されるシナリオを考えてみましょう。医師たちはその可能性に興奮しています。しかし、それを日常のケアに組み込む前に、
倫理的AI/公正なAIの重要性と回避すべきバイアスの種類
人工知能 (AI) の急成長分野では、倫理的配慮と公平性に重点を置くことは、道徳的義務を超えたものであり、社会の基本的な必要性です。
AI 医療記録の要約: 定義、課題、ベスト プラクティス
ヘルスケア業界における医療記録の増加は、課題であると同時にチャンスでもあります。あらゆる細部が調和する世界を想像してみてください。
臨床データの抽象化: 定義、プロセスなど
病院や診療所では毎年何千人もの患者が来院します。そのためには膨大な数の専任の医師と看護師が必要です。彼らはケアを提供するために精力的に働いています
医療における合成データ: 定義、利点、および課題
研究者が新薬を開発しているシナリオを想像してみてください。検査には広範な患者データが必要ですが、プライバシーとプライバシーに関する重大な懸念があります。
匿名化に関する HIPAA 専門家の決定
医療保険の相互運用性と責任に関する法律 (HIPAA) は、医療における患者データの保護の基準を定めています。この重要な側面は、Protected の匿名化です。
NLP による先駆的な腫瘍学研究: Shaip の画期的な進歩
ケーススタディをダウンロード がんを克服するという探求においては、データは決意と同じくらい重要です。 Shaip では、大きな飛躍を可能にしたことを誇りに思っています
放射線科における自然言語処理 (NLP) の力: 診断と効率の向上
放射線医学は医療において重要な役割を果たしています。 CTスキャン、X線、MRIなどの画像技術を使用して、さまざまな状態を診断および治療します。 自然言語
腫瘍学における自然言語処理 (NLP) の役割
がんは世界的に重大な健康上の課題を引き起こしています。 これは、細胞が制御されずに増殖および拡散するときに発生します。 死因の第XNUMX位です
人間のフィードバックからの強化学習について知っておくべきことすべて
2023 年には、ChatGPT などの AI ツールの導入が大幅に増加しました。 この急増により活発な議論が始まり、人々は AI の利点について議論しています。
自動車業界における AI の力
AI を自動車に統合することに関して、世界は顕著な岐路に立たされています。 AI が交通量の多い道路を運転し、自分の車の状態を管理しているところを想像してみてください。
業界全体にわたるテキスト読み上げの利点
Text-to-speech (TTS) テクノロジーは、書かれたテキストを話し言葉に変換する革新的なソリューションです。 いくつかの業界でゲームチェンジャーとなり、革命を起こしました
データ匿名化ガイド: 初心者が知っておくべきことすべて (2024 年)
デジタル変革の時代において、医療機関は業務をデジタル プラットフォームに急速に移行しています。 これによりプロセスの効率化と合理化がもたらされますが、

OCR – 定義、利点、課題、および使用例 [インフォグラフィック]
OCR は、機械が印刷されたテキストと画像を読み取れるようにする技術です。 これは、保存や処理のためにドキュメントをデジタル化するなどのビジネス アプリケーションや、経費精算のために領収書をスキャンするなどの消費者向けアプリケーションでよく使用されます。

会話型AI2022の状態
The State ofConversational AI 2022 What isConversational AI? A programmatic and intelligent way ofoffering a conversational experience tomimic conversations with


データラベリングとは何ですか? 初心者が知っておくべきことすべて
Download Infographics Intelligent AI models need to be trained extensively for being able to identify patterns, objects, and eventually make