


Q&Aペア
テキストの要約
画像のキャプション
オーディオの生成
LLM データの評価
LLM データの比較
合成対話の作成
画像の要約、評価、検証
Q&Aペア
Q/A ペアの作成
キーワードクエリの作成
シーケンスQ&A
RAG Q/A 検証
Q/A ペアの作成

キーワードクエリの作成

シーケンスQ&A

RAG Q/A 検証

テキストの要約
パラサマリー
電子メールの要約
会話の要約
パラサマリー

電子メールの要約
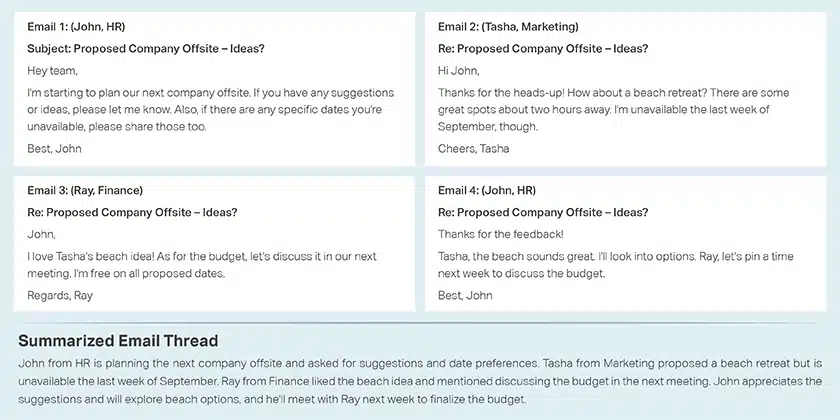
会話の要約
画像のキャプション

オーディオの生成

LLM データの評価

LLM データの比較

合成対話の作成
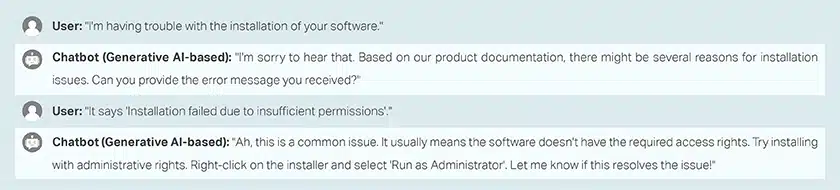
チャットボットトレーニング Q/A
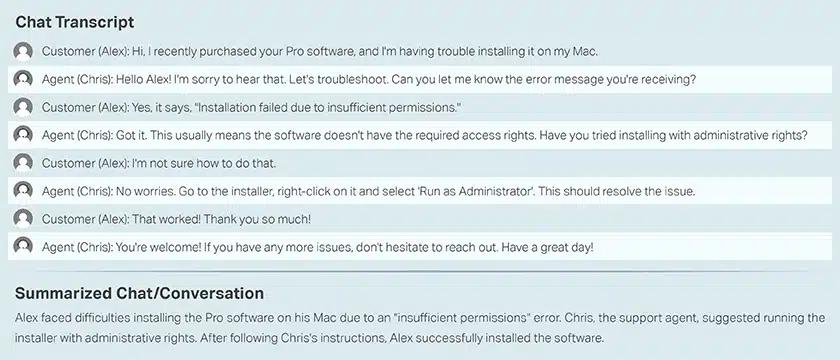
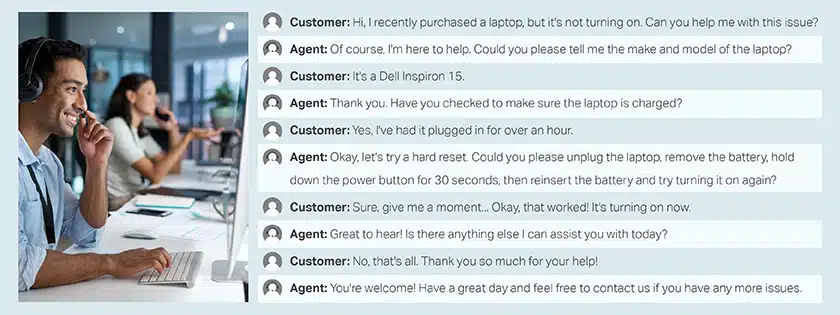
コールセンターでの顧客とエージェントの会話
チャットボットトレーニング Q/A
コールセンターでの顧客とエージェントの会話
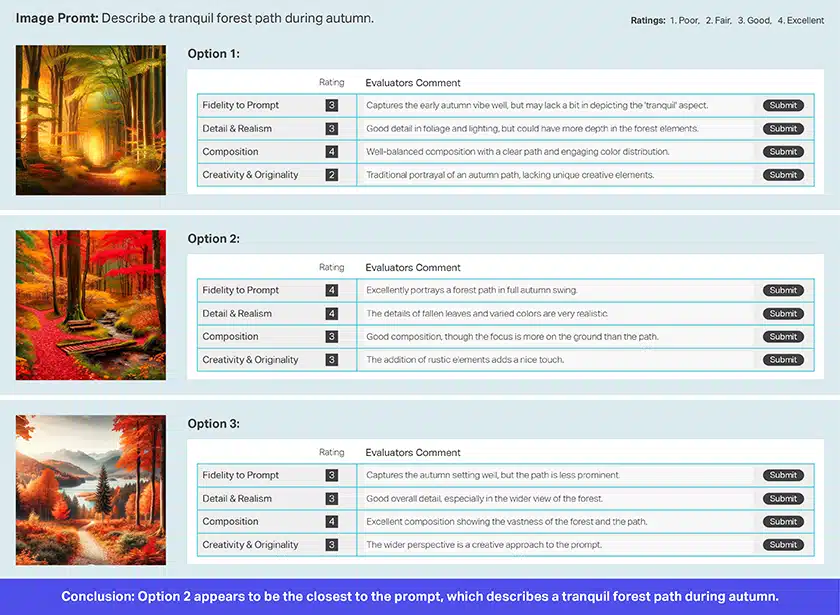
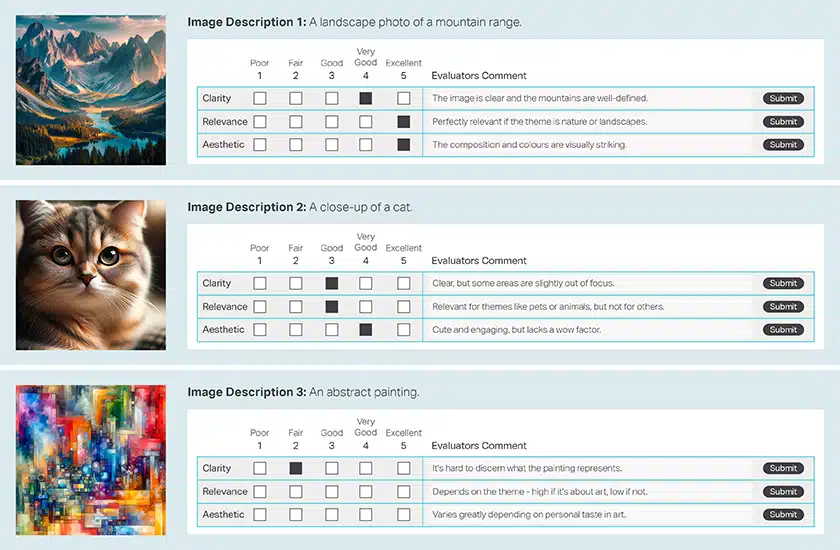
画像の要約、評価、検証
画像の評価
画像の検証
画像の要約
画像の評価
画像の検証
画像の要約




臨床NLPの作成は重要なタスクであり、解決するには膨大なドメインの専門知識が必要です。 この分野では、あなたがGoogleより数年進んでいることがはっきりとわかります。 私はあなたと一緒に働き、あなたをスケーリングしたいと思います。
グーグル株式会社 取締役
私のエンジニアリングチームは、ヘルスケア音声APIの開発中にShaipのチームと2年以上協力しました。 私たちは、ヘルスケア固有のNLPで行われた彼らの仕事と、複雑なデータセットで達成できることに感銘を受けました。
グーグル株式会社 エンジニアリング責任者