

大規模言語モデルとは何ですか?
Large Language Model (LLM) は、人間のようなテキストを処理、理解、生成するように設計された高度な人工知能 (AI) システムです。 これらは深層学習技術に基づいており、通常、Web サイト、書籍、記事などのさまざまなソースからの数十億の単語を含む大規模なデータセットでトレーニングされています。 この広範なトレーニングにより、LLM は言語、文法、文脈、さらには一般知識のいくつかの側面のニュアンスを把握できるようになります。
OpenAI の GPT-3 などの一部の人気のある LLM は、トランスフォーマーと呼ばれる一種のニューラル ネットワークを採用しており、これにより複雑な言語タスクを優れた熟練度で処理できるようになります。 これらのモデルは、次のような幅広いタスクを実行できます。
- 質問に答える
- テキストの要約
- 言語の翻訳
- コンテンツの生成
- ユーザーとのインタラクティブな会話にも参加可能
LLM は進化し続けるため、顧客サービスやコンテンツ作成から教育や研究に至るまで、業界全体のさまざまなアプリケーションを強化および自動化する大きな可能性を秘めています。 しかし、それらはまた、偏見のある行動や誤用などの倫理的および社会的懸念も引き起こしており、テクノロジーの進歩に伴い対処する必要があります。

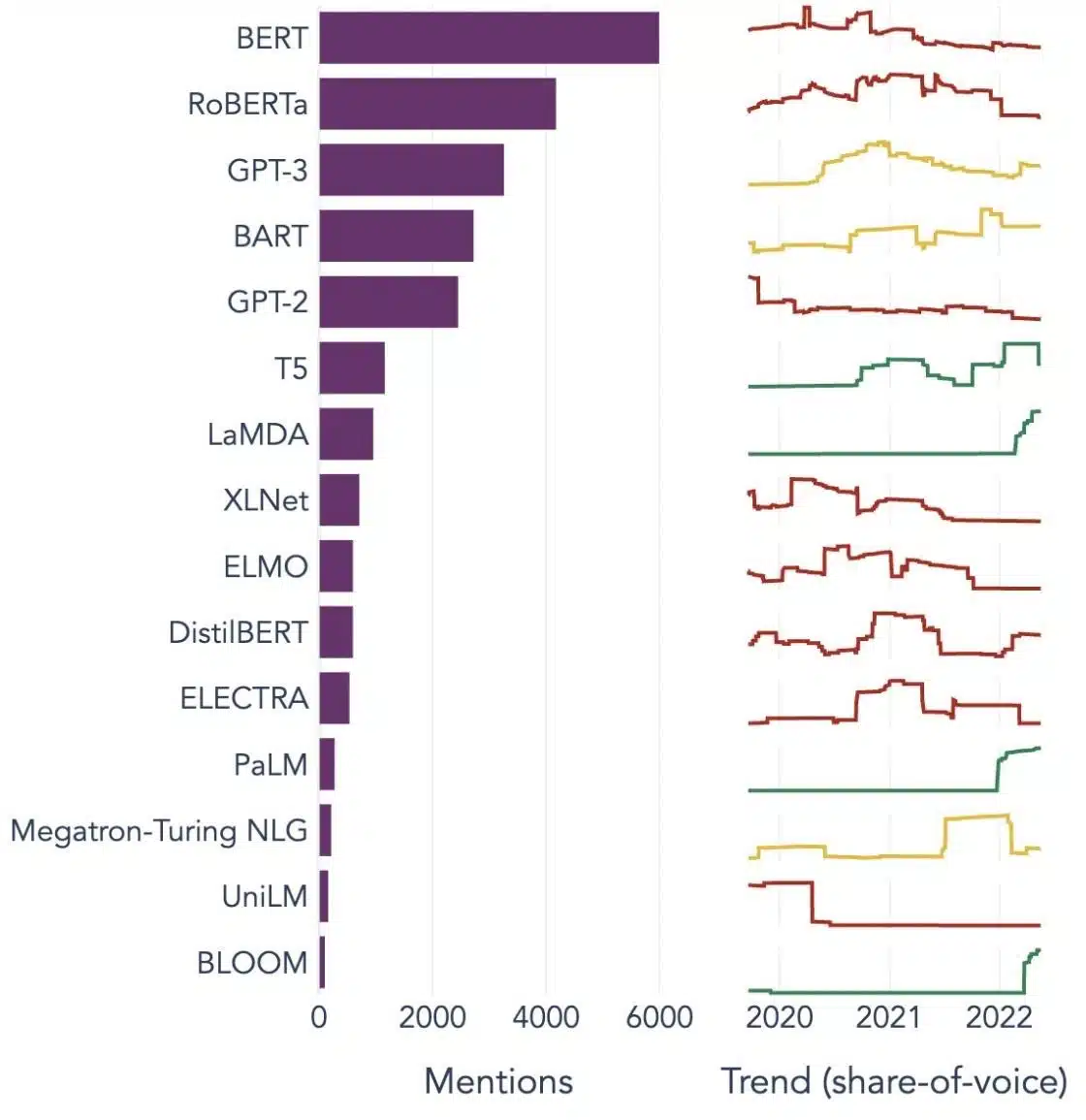
LLM モデルはどのようにトレーニングされますか?
大規模言語モデル (LLM) のトレーニングは、いくつかの重要な手順を伴う非常に困難な作業です。 以下に、プロセスを段階的に簡単にまとめます。
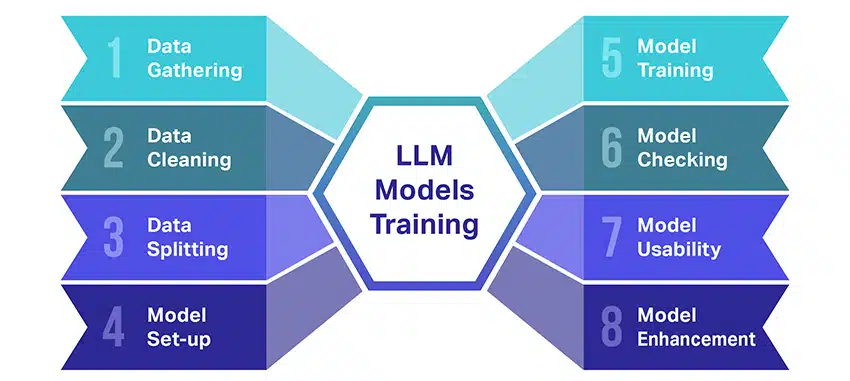
- テキストデータの収集: LLM のトレーニングは、膨大な量のテキスト データの収集から始まります。 このデータは、書籍、Web サイト、記事、またはソーシャル メディア プラットフォームから取得することができます。 その目的は、人間の言語の豊かな多様性を捉えることです。
- データのクリーンアップ: 生のテキスト データは、前処理と呼ばれるプロセスで整理されます。 これには、不要な文字を削除する、テキストをトークンと呼ばれる小さな部分に分割する、すべてをモデルが使用できる形式に変換するなどのタスクが含まれます。
- データの分割: 次に、クリーンなデータが XNUMX つのセットに分割されます。 XNUMX つのセットであるトレーニング データは、モデルのトレーニングに使用されます。 もう XNUMX つのセットである検証データは、後でモデルのパフォーマンスをテストするために使用されます。
- モデルのセットアップ: 次に、アーキテクチャとして知られる LLM の構造が定義されます。 これには、ニューラル ネットワークの種類を選択し、ネットワーク内の層や隠れユニットの数などのさまざまなパラメーターを決定することが含まれます。
- モデルをトレーニングする: これから本格的な訓練が始まります。 LLM モデルは、トレーニング データを見て学習し、これまでに学習した内容に基づいて予測を行い、内部パラメーターを調整して予測と実際のデータの差異を小さくします。
- モデルの確認: LLM モデルの学習は検証データを使用してチェックされます。 これは、モデルのパフォーマンスがどの程度優れているかを確認し、パフォーマンスを向上させるためにモデルの設定を調整するのに役立ちます。
- モデルの使用: トレーニングと評価が完了すると、LLM モデルを使用できるようになります。 与えられた新しい入力に基づいてテキストを生成するアプリケーションやシステムに統合できるようになりました。
- モデルの改善: 最後に、常に改善の余地があります。 LLM モデルは、更新されたデータを使用したり、フィードバックや実際の使用状況に基づいて設定を調整したりすることで、時間の経過とともにさらに改良することができます。
このプロセスには、強力な処理装置や大容量ストレージなどの大量の計算リソースと、機械学習の専門知識が必要であることに注意してください。 そのため、通常は、必要なインフラストラクチャと専門知識にアクセスできる専門の研究組織または企業によって行われます。
LLM は教師あり学習と教師なし学習のどちらに依存しますか?
大規模な言語モデルは通常、教師あり学習と呼ばれる方法を使用してトレーニングされます。 簡単に言えば、これは、正解を示す例から学ぶことを意味します。
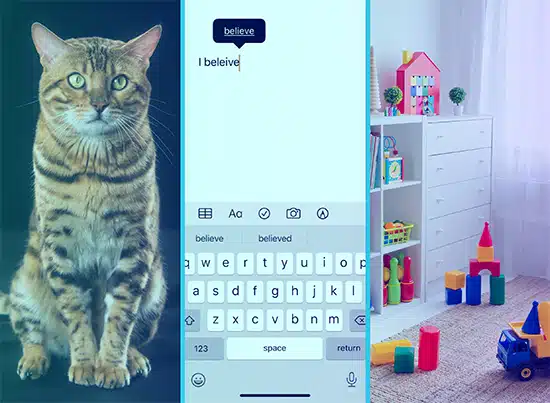 子供に絵を見せて言葉を教えていると想像してみてください。 猫の写真を見せて「猫」と言うと、子供たちはその写真とその言葉を結びつけることを学びます。 これが教師あり学習の仕組みです。 モデルには大量のテキスト (「画像」) と対応する出力 (「単語」) が与えられ、それらを照合することを学習します。
子供に絵を見せて言葉を教えていると想像してみてください。 猫の写真を見せて「猫」と言うと、子供たちはその写真とその言葉を結びつけることを学びます。 これが教師あり学習の仕組みです。 モデルには大量のテキスト (「画像」) と対応する出力 (「単語」) が与えられ、それらを照合することを学習します。
したがって、LLM に文を与えると、LLM は例から学んだことに基づいて次の単語またはフレーズを予測しようとします。 このようにして、意味があり、コンテキストに適合するテキストを生成する方法を学習します。
そうは言っても、LLM は教師なし学習を少し使用することもあります。 これは、子供にさまざまなおもちゃでいっぱいの部屋を探索させ、それらについて自分で学ばせるようなものです。 モデルは、「正しい」答えを教えられることなく、ラベルのないデータ、学習パターン、構造を調べます。
教師あり学習は、ラベル付き出力データを使用しない教師なし学習とは対照的に、入力と出力でラベル付けされたデータを使用します。
一言で言えば、LLM は主に教師あり学習を使用してトレーニングされますが、探索的分析や次元削減などの機能を強化するために教師なし学習を使用することもできます。
大規模な言語モデルをトレーニングするために必要なデータ量 (GB) はどれくらいですか?
音声データ認識と音声アプリケーションの可能性の世界は広大であり、それらは多くのアプリケーションのためにいくつかの業界で使用されています。
大規模な言語モデルのトレーニングは、特に必要なデータに関しては、万能のプロセスではありません。 それは多くのことに依存します。
- モデルのデザインです。
- どのような仕事をする必要があるのでしょうか?
- 使用しているデータの種類。
- どの程度のパフォーマンスを発揮したいですか?
とはいえ、LLM のトレーニングには通常、大量のテキスト データが必要です。 しかし、私たちはどれくらいの規模のことを話しているのでしょうか? そうですね、ギガバイト (GB) をはるかに超えて考えてください。 私たちは通常、テラバイト (TB) またはペタバイト (PB) 規模のデータを検討しています。
最大の LLM の 3 つである GPT-XNUMX を考えてみましょう。 で訓練されています 570GBのテキストデータ。 小規模な LLM では、必要な容量は少なくなり、おそらく 10 ~ 20 GB、あるいは 1 GB のギガバイトで済むかもしれませんが、それでもかなりの量です。

しかし、それはデータのサイズだけではありません。 品質も重要です。 モデルが効果的に学習できるように、データはクリーンで多様である必要があります。 また、必要なコンピューティング能力、トレーニングに使用するアルゴリズム、使用しているハードウェア設定など、パズルの他の重要な部分を忘れることはできません。 これらすべての要素が LLM のトレーニングに大きな役割を果たします。
大規模言語モデルの台頭: なぜそれが重要なのか
LLM はもはや単なる概念や実験ではありません。 私たちのデジタル環境において、それらはますます重要な役割を果たしています。 しかし、なぜこのようなことが起こっているのでしょうか? これらの LLM はなぜそれほど重要なのでしょうか? いくつかの重要な要素を詳しく見てみましょう。
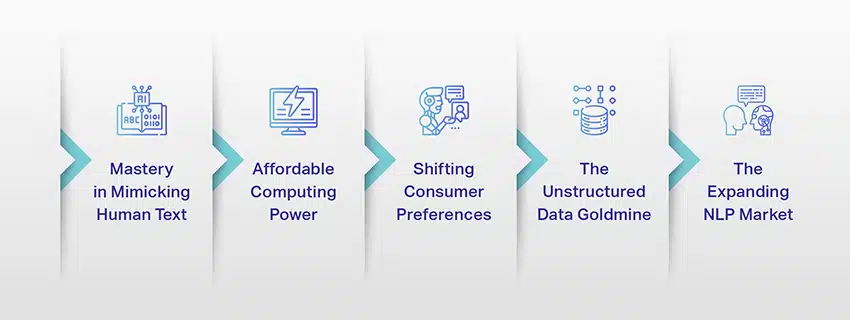
人間のテキストを模倣することに熟達する
LLM は、言語ベースのタスクの処理方法を変革しました。 これらのモデルは、堅牢な機械学習アルゴリズムを使用して構築されており、文脈、感情、さらには皮肉を含む人間の言語のニュアンスをある程度理解する能力を備えています。 人間の言語を模倣するこの能力は単なる目新しいものではなく、重要な意味を持っています。
LLM の高度なテキスト生成機能により、コンテンツの作成から顧客サービスのやり取りに至るまで、あらゆるものを強化できます。
デジタル アシスタントに複雑な質問をして、理にかなっているだけでなく、一貫性と関連性があり、会話のような口調で答えられる答えが得られることを想像してみてください。 それが LLM によって可能になるのです。 これらは、より直観的で魅力的な人間と機械の対話を促進し、ユーザー エクスペリエンスを豊かにし、情報へのアクセスを民主化します。
手頃なコンピューティング能力
LLM の台頭は、コンピューティング分野での並行した開発がなければ不可能でした。 より具体的には、計算リソースの民主化は、LLM の進化と導入において重要な役割を果たしてきました。
クラウドベースのプラットフォームは、ハイパフォーマンス コンピューティング リソースへの前例のないアクセスを提供します。 このようにして、小規模な組織や独立した研究者でも、洗練された機械学習モデルをトレーニングできます。
さらに、処理装置 (GPU や TPU など) の改善と分散コンピューティングの台頭により、数十億のパラメーターを使用してモデルをトレーニングすることが可能になりました。 このコンピューティング能力へのアクセスのしやすさの向上により、LLM の成長と成功が可能になり、現場でのさらなるイノベーションとアプリケーションにつながります。
消費者の嗜好の変化
今日の消費者は単に答えを求めているわけではありません。 彼らは魅力的で共感できるやり取りを望んでいます。 デジタル テクノロジーを使用して成長する人が増えるにつれ、より自然で人間らしく感じられるテクノロジーへのニーズが高まっていることは明らかです。LLM は、これらの期待に応える比類のない機会を提供します。 これらのモデルは、人間のようなテキストを生成することで、魅力的でダイナミックなデジタル エクスペリエンスを作成し、ユーザーの満足度とロイヤリティを向上させることができます。 顧客サービスを提供する AI チャットボットであっても、ニュース更新を提供する音声アシスタントであっても、LLM は私たちをよりよく理解する AI の時代の到来をもたらします。
非構造化データの宝庫
電子メール、ソーシャル メディアの投稿、顧客レビューなどの非構造化データは、洞察の宝庫です。 以上であると推定されています 視聴者の38%が 企業データの一部は構造化されておらず、急速に増加しています 視聴者の38%が XNUMX年当たり。 このデータは、適切に活用すればビジネスにとって宝の山です。
ここでは、そのようなデータを大規模に処理して理解する能力を備えた LLM が活躍します。 感情分析、テキスト分類、情報抽出などのタスクを処理できるため、貴重な洞察が得られます。
ソーシャル メディアの投稿から傾向を特定する場合でも、レビューから顧客感情を測定する場合でも、LLM は企業が大量の非構造化データを操作し、データに基づいた意思決定を行うのを支援します。
拡大するNLP市場
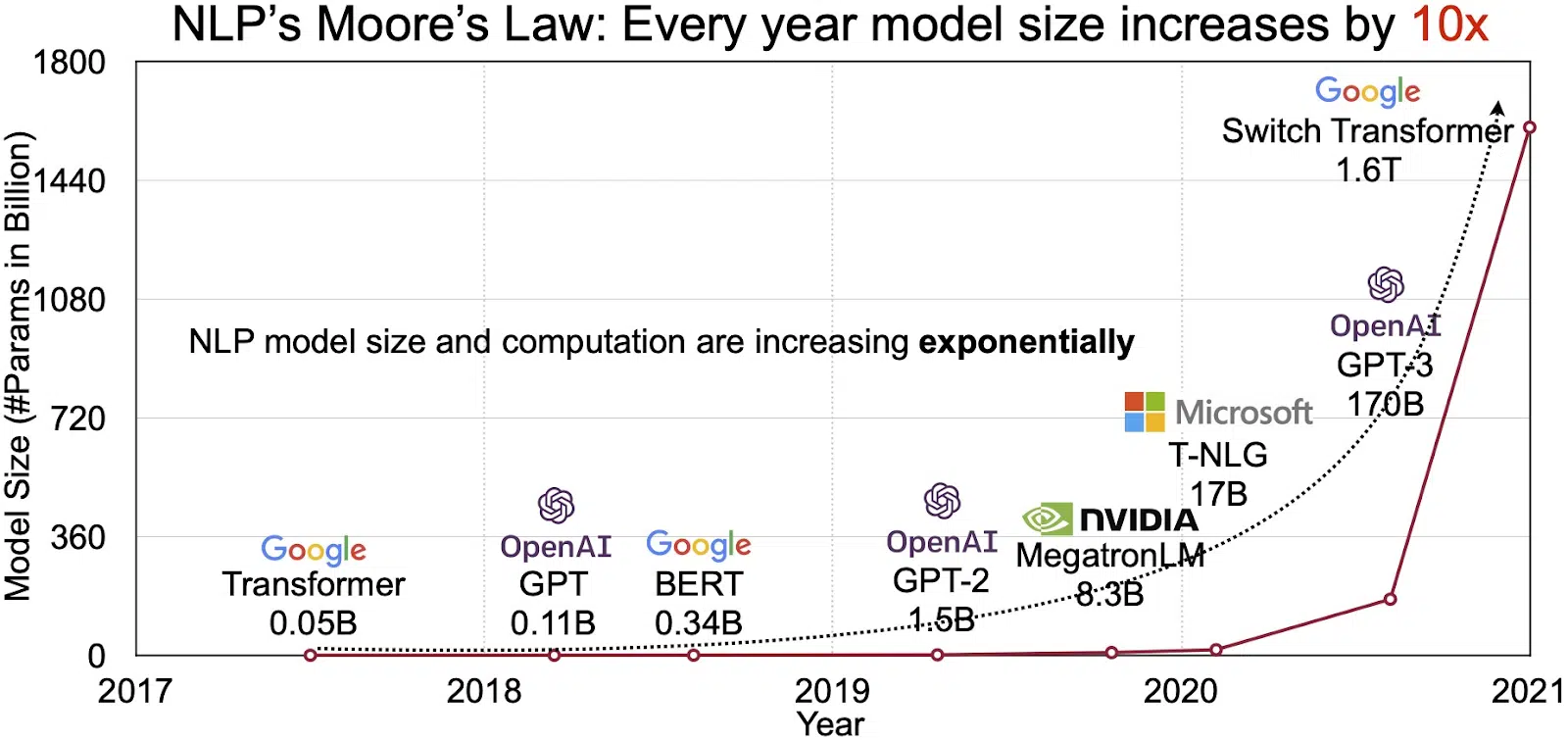
LLM の可能性は、急速に成長する自然言語処理 (NLP) 市場に反映されています。 アナリストは、NLP 市場が今後拡大すると予測しています。 11 年に 2020 億ドル、35 年までに 2026 億ドル以上。 しかし、拡大しているのは市場規模だけではありません。 モデル自体も、物理的なサイズと処理するパラメーターの数の両方で増加しています。 以下の図 (画像出典: リンク) に見られるように、長年にわたる LLM の進化は、LLM の複雑さと容量の増大を強調しています。
大規模言語モデルの一般的な使用例
以下は、LLM の最も一般的な使用例の一部です。
- 自然言語テキストの生成: 大規模言語モデル (LLM) は、人工知能と計算言語学の能力を組み合わせて、自然言語でテキストを自律的に生成します。 記事を書いたり、曲を作成したり、ユーザーと会話したりするなど、さまざまなユーザーのニーズに応えることができます。
- 機械による翻訳: LLM を効果的に使用すると、任意の言語ペア間でテキストを翻訳できます。 これらのモデルは、リカレント ニューラル ネットワークなどの深層学習アルゴリズムを活用して、ソース言語とターゲット言語の両方の言語構造を理解することで、ソース テキストから目的の言語への翻訳を容易にします。
- オリジナルコンテンツの作成: LLM は、マシンが一貫性のある論理的なコンテンツを生成するための道を開きました。 このコンテンツは、ブログ投稿、記事、その他の種類のコンテンツの作成に使用できます。 モデルは、深い深層学習の経験を活用して、斬新でユーザーフレンドリーな方法でコンテンツをフォーマットおよび構造化します。
- 感情の分析: 大規模言語モデルの興味深い応用例の XNUMX つは感情分析です。 この場合、モデルは、注釈付きテキストに存在する感情状態とセンチメントを認識して分類するようにトレーニングされます。 このソフトウェアは、ポジティブ、ネガティブ、中立、その他の複雑な感情などの感情を識別できます。 これにより、さまざまな製品やサービスに関する顧客のフィードバックや意見に関する貴重な洞察が得られます。
- テキストの理解、要約、分類: LLM は、AI ソフトウェアがテキストとそのコンテキストを解釈するための実行可能な構造を確立します。 LLM は、膨大な量のデータを理解して精査するようにモデルに指示することで、AI モデルがさまざまな形式やパターンのテキストを理解、要約し、さらには分類できるようにします。
- 質問への回答: 大規模言語モデルは、質問応答 (QA) システムに、ユーザーの自然言語クエリを正確に認識して応答する機能を備えています。 このユースケースの一般的な例としては、ChatGPT や BERT が挙げられます。これらは、クエリのコンテキストを調べ、膨大なテキストのコレクションを選別して、ユーザーの質問に関連する応答を提供します。

品詞 (POS) タグ付け
文内の単語には、動詞、名詞、形容詞などの文法機能がタグ付けされています。このプロセスは、モデルが文法と単語間のつながりを理解するのに役立ちます。

固有表現抽出(NER)
文内の組織、場所、人物などの名前付きエンティティがマークされます。 この演習は、モデルが単語やフレーズの意味論的な意味を解釈するのに役立ち、より正確な応答を提供します。

感情分析
テキスト データにはポジティブ、ニュートラル、ネガティブなどのセンチメント ラベルが割り当てられており、モデルが文章の感情的な基調を把握するのに役立ちます。 これは、感情や意見を含む質問に応答する場合に特に役立ちます。
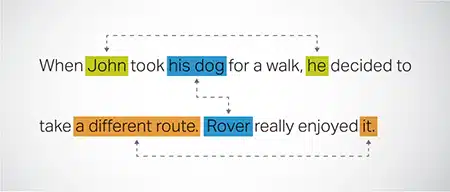
相互参照の解像度
テキストの異なる部分で同じエンティティが参照されているインスタンスを特定して解決します。 このステップは、モデルが文のコンテキストを理解するのに役立ち、一貫した応答につながります。
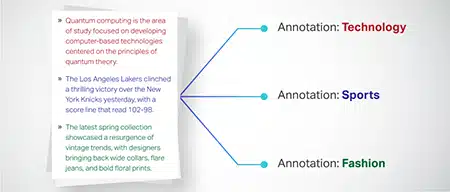
テキスト分類
テキスト データは、製品レビューやニュース記事などの事前定義されたグループに分類されます。 これは、モデルがテキストのジャンルやトピックを識別し、より適切な応答を生成するのに役立ちます。
シャイプの捧げもの
シャイプ は、組織がデータを管理、分析し、最大限に活用できるよう支援する幅広いサービスを提供しています。
データWebスクレイピング
Shaip が提供する主要なサービスの XNUMX つはデータ スクレイピングです。 これには、ドメイン固有の URL からのデータの抽出が含まれます。 Shaip は、自動化されたツールと技術を活用することで、さまざまな Web サイト、製品マニュアル、技術文書、オンライン フォーラム、オンライン レビュー、顧客サービス データ、業界規制文書などから大量のデータを迅速かつ効率的に収集できます。このプロセスは、次のような場合に企業にとって非常に貴重です。多数のソースから関連性のある具体的なデータを収集する。

機械翻訳
さまざまな言語間でテキストを翻訳するための、対応する文字起こしと組み合わせた広範な多言語データセットを使用してモデルを開発します。 このプロセスは、言語上の障害を取り除き、情報へのアクセスを促進します。
タクソノミーの抽出と作成
Shaip は分類法の抽出と作成に役立ちます。 これには、さまざまなデータ ポイント間の関係を反映する構造化された形式にデータを分類して分類することが含まれます。 これは、企業がデータを整理し、アクセスしやすく分析しやすくする場合に特に役立ちます。 たとえば、電子商取引ビジネスでは、製品データが製品タイプ、ブランド、価格などに基づいて分類され、顧客が製品カタログ内を簡単にナビゲートできるようになります。
データ収集
当社のデータ収集サービスは、生成 AI アルゴリズムのトレーニングとモデルの精度と有効性の向上に必要な重要な現実世界または合成データを提供します。 データは、データのプライバシーとセキュリティを念頭に置きながら、公平かつ倫理的かつ責任をもって調達されます。

質疑応答
質問応答 (QA) は、人間の言語で質問に自動的に答えることに重点を置いた自然言語処理の下位分野です。 QA システムは広範なテキストとコードでトレーニングされており、事実、定義、意見に基づく質問など、さまざまな種類の質問を処理できます。 カスタマー サポート、ヘルスケア、サプライ チェーンなどの特定の分野に合わせた QA モデルを開発するには、ドメインの知識が不可欠です。 ただし、生成的 QA アプローチを使用すると、モデルはドメインの知識がなくても、コンテキストのみに依存してテキストを生成できます。
当社の専門家チームは、包括的な文書やマニュアルを注意深く調査して質問と回答のペアを生成し、企業向けの生成 AI の作成を促進します。 このアプローチでは、広範なコーパスから関連情報をマイニングすることで、ユーザーの問い合わせに効果的に対処できます。 当社の認定専門家は、さまざまなトピックや分野にわたる最高品質の Q&A ペアの作成を保証します。

テキストの要約
当社のスペシャリストは、包括的な会話や長い対話を抽出し、広範なテキスト データから簡潔で洞察力に富んだ要約を提供することができます。

テキスト生成
ニュース記事、フィクション、詩など、さまざまなスタイルのテキストの広範なデータセットを使用してモデルをトレーニングします。 これらのモデルは、ニュース記事、ブログ エントリ、ソーシャル メディア投稿などのさまざまな種類のコンテンツを生成でき、コンテンツ作成のための費用対効果が高く、時間を節約できるソリューションを提供します。
音声認識
さまざまなアプリケーション向けに音声言語を理解できるモデルを開発します。 これには、音声起動アシスタント、ディクテーション ソフトウェア、リアルタイム翻訳ツールが含まれます。 このプロセスには、対応するトランスクリプトと組み合わせた、話し言葉の音声録音で構成される包括的なデータセットの利用が含まれます。

製品の推奨事項
顧客が購入する傾向にある製品を示すラベルなど、顧客の購入履歴の広範なデータセットを使用してモデルを開発します。 お客様へ的確な提案を行い、売上の向上と顧客満足度の向上を目指します。
画像のキャプション
最先端の AI 主導の画像キャプション サービスで、画像解釈プロセスに革命をもたらします。 私たちは、正確で文脈的に意味のある説明を作成することで、写真に活力を吹き込みます。 これにより、視聴者にとってビジュアル コンテンツとの革新的なエンゲージメントとインタラクションの可能性への道が開かれます。

テキスト読み上げサービスのトレーニング
AI モデルのトレーニングに最適な、人間の音声録音で構成される広範なデータセットを提供します。 これらのモデルは、アプリケーション向けに自然で魅力的な音声を生成できるため、ユーザーに独特で臨場感のあるサウンド エクスペリエンスを提供します。



