


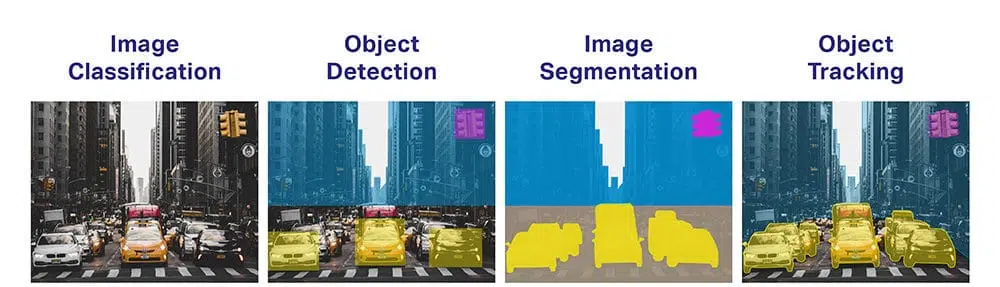
- オブジェクトの分類:オブジェクトの幅広いカテゴリは何ですか?
- オブジェクトの識別: 特定のオブジェクトのどのタイプがありますか?
- オブジェクトの検証: 写真のオブジェクトはどれですか?
- オブジェクト検出: 写真のオブジェクトはどこにありますか?
- オブジェクトのランドマーク検出: 写真に写っている被写体のポイントは何ですか?
- オブジェクトのセグメンテーション: 画像内のオブジェクトに属するピクセルは何ですか?
- オブジェクト認識: この写真にはどのようなオブジェクトがあり、どこにありますか?

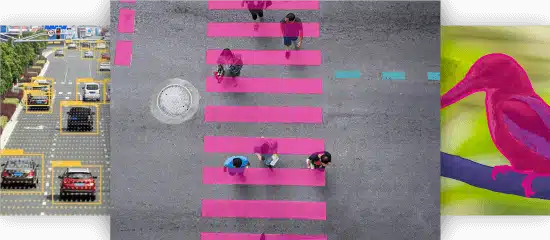

コレクション
アノテーション
転写
使用事例
コレクション

画像コレクション

ビデオコレクション
アノテーション

バウンディングボックス
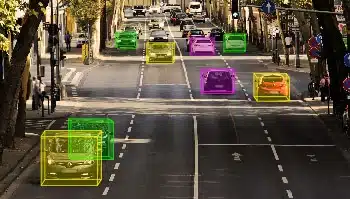
3D直方体
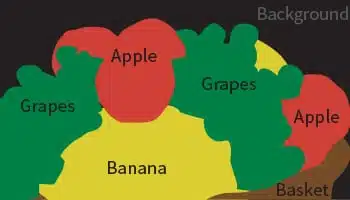
セマンティックセグメンテーション

ポリゴンアノテーション

ランドマーク注釈

ラインセグメンテーション
転写

画像の文字起こし
ビデオ転写
使用事例

画像分類
画像のセグメンテーション

画像キーポイント注釈

ビデオ分類
ビデオセグメンテーション

- 使用事例: 車載ADASモデル
- フォーマット: 画像
- ボリューム: 455,000+
- 注釈: いいえ

- 使用事例: ランドマークの検出
- フォーマット: 画像
- ボリューム: 80,000+
- 注釈: いいえ

- 使用事例: 歩行者追跡
- フォーマット: 動画
- ボリューム: 84,500+
- 注釈: 有り

- 使用事例: 食品認識
- フォーマット: 画像
- ボリューム: 55,000+
- 注釈: 有り

ヘルスケアAI
MLモデルをトレーニングして、皮膚画像のがんのほくろを検出したり、MRIスキャンや患者のX線で症状を見つけたりします。

顔認識
MLモデルをトレーニングして、顔の特徴に基づいて人物の画像を識別し、顔のプロファイルのデータベースと比較して、人物を検出してタグ付けします。

地理空間アプリケーション
ジオプロセシング用のデータセットを準備するための衛星画像とUAV写真の注釈、およびGeo.AI用の3D点群に注釈を付けます。

拡張現実
ARヘッドセットを使用して、仮想オブジェクトを現実の世界に配置します。 壁、テーブルトップ、床などの平面を検出できます。これは、奥行きと寸法を確立し、仮想オブジェクトを物理世界に配置する上で非常に重要な部分です。

自己駆動車
複数のカメラが異なる角度からビデオをキャプチャして、近くの信号機、道路、車、物体、歩行者の境界を特定し、自動運転車が車両を自動操縦し、乗客を安全に運転しながら障害物にぶつからないように訓練します。

小売/ eコマース
小売業のコンピュータービジョンにより、アプリケーションは顧客の購入パターンに基づいてパーソナライズされた推奨事項を提供し、棚管理、支払いなどの業務をスピードアップできます。




のワークプ
専任の訓練を受けたチーム:
- データ作成、ラベリング、QAのための30,000人以上の協力者
- 資格のあるプロジェクト管理チーム
- 経験豊富な製品開発チーム
- タレントプールソーシング&オンボーディングチーム

プロセス
最高のプロセス効率が保証されます:
- 堅牢な6シックスシグマステージゲートプロセス
- シックスシグマ黒帯の専任チーム–主要なプロセス所有者と品質コンプライアンス
- 継続的改善とフィードバックループ

プラットフォーム
特許取得済みのプラットフォームには次のような利点があります。
- Webベースのエンドツーエンドプラットフォーム
- 非の打ちどころのない品質
- より速いTAT
- シームレスな配信
のワークプ
専任の訓練を受けたチーム:
- データ作成、ラベリング、QAのための30,000人以上の協力者
- 資格のあるプロジェクト管理チーム
- 経験豊富な製品開発チーム
- タレントプールソーシング&オンボーディングチーム
プロセス
最高のプロセス効率が保証されます:
- 堅牢な6シックスシグマステージゲートプロセス
- シックスシグマ黒帯の専任チーム–主要なプロセス所有者と品質コンプライアンス
- 継続的改善とフィードバックループ
プラットフォーム
特許取得済みのプラットフォームには次のような利点があります。
- Webベースのエンドツーエンドプラットフォーム
- 非の打ちどころのない品質
- より速いTAT
- シームレスな配信