
AI開発の障害を克服するための鍵:より信頼性の高いデータ
今日、平均的な人は、1969年にNASAが月面着陸をやめなければならなかった数百万倍の計算能力をポケットに持っています。豊富な計算能力を便利に示す同じユビキタスデバイスは、AIの黄金時代のもう90つの前提条件も満たしています。豊富なデータ。 Information Overload Research Groupの洞察によると、世界のデータのXNUMX%は過去XNUMX年間に作成されたものです。 コンピューティングパワーの指数関数的成長がデータ生成の同様に急激な成長と最終的に収束した今、AIデータの革新は非常に爆発的であり、一部の専門家は第XNUMX次産業革命を急いで開始すると考えています。
National Venture Capital Associationのデータによると、AIセクターは6.9年の第2020四半期に過去最高のXNUMX億ドルの投資を記録しました。すでに私たちの周りで利用されているため、AIツールの可能性を理解することは難しくありません。 AI製品のより目に見えるユースケースのいくつかは、SpotifyやNetflixなどのお気に入りのアプリケーションの背後にあるレコメンデーションエンジンです。 聴く新しいアーティストや一気見する新しいテレビ番組を見つけるのは楽しいですが、これらの実装はかなり低リスクです。 他のアルゴリズムは、テストのスコアを評価し(学生が大学に受け入れられる場所を部分的に決定します)、さらに他のアルゴリズムは、候補者の履歴書をふるいにかけて、どの応募者が特定の仕事に就くかを決定します。 一部のAIツールは、乳がんをスクリーニングするAIモデル(医師よりも優れている)など、生死にかかわる影響を与えることさえあります。
AI開発の実際の例と、次世代の変革ツールの作成を争うスタートアップの数の両方が着実に増加しているにもかかわらず、効果的な開発と実装への課題は残っています。 特に、AI出力は入力が許す限り正確であるため、品質が最優先されます。

複雑なコンプライアンス要求のナビゲート
質の高いデータを見つけるのはそれほど難しいことではなかったかのように、AIデータの革新から最大の利益を得る立場にある業界の中には、最も厳しく規制されているものもあります。 ヘルスケアはおそらく最良の例であり、HITインフラストラクチャの調査によると、業界関係者の91%が、テクノロジーがケアへのアクセスを改善できると考えていますが、75%が患者のセキュリティとプライバシーに対する脅威と見なしているという事実により、楽観的な見方は和らげられています。 —そして危険にさらされているのは患者だけではありません。
医療保険の相互運用性と説明責任に関する法律によって制定された抜本的な規制は、現在、ヨーロッパの一般データ保護規則、米国のカリフォルニア消費者プライバシー法、シンガポールの個人データ保護法など、さまざまな地域のデータコンプライアンスのハードルと交差しています。 これらの地域の規制にはさらに多くの規制が加わり、遠隔医療が医療データのより重要な情報源として浮上するにつれて、規制は輸送中の患者データをさらに厳しく把握する可能性があります。 その結果、Shaipの安全で準拠したクラウドプラットフォームは、AI製品をトレーニングするために医療データを収集してアクセスするためのさらに価値のある手段であることが証明されます。
個人を特定できる情報はAI開発にとって重大な脅威となる可能性がありますが、完全に準拠した実装でさえ、多様なトレーニングデータのみで得られるような正確な結果を提供できない場合はリスクがあります。 Journal of the American Medical Associationの2020年の研究では、医療分野の機械学習アルゴリズムは、カリフォルニア、ニューヨーク、マサチューセッツの患者からのデータを使用してトレーニングされることが最も多いことが示されました。 これらの患者が米国の人口のXNUMX分のXNUMX未満であることを考えると、世界の他の地域は言うまでもなく、これらのモデルがどのように偏った結果を生み出すことができるかを想像するのは難しいです。

 Shaipは、準拠した地理的に多様な情報を保護することの難しさを認識し、正確なアルゴリズムを構築することを目的として特別にキュレーションされたさまざまな地域からライセンスを受けた医療データを提供しています。 このデータは、医療記録や請求情報などのテキスト、CTスキャンなどの医療診断画像、医師からの音声メモや医師と患者間の会話などの音声、さらにはMRI結果からのビデオの形式で提供されます。 また、完全に匿名化および匿名化されており、国内および国際的なデータを管理する規制の増加に伴う倫理的および財務的影響から組織を保護します。
Shaipは、準拠した地理的に多様な情報を保護することの難しさを認識し、正確なアルゴリズムを構築することを目的として特別にキュレーションされたさまざまな地域からライセンスを受けた医療データを提供しています。 このデータは、医療記録や請求情報などのテキスト、CTスキャンなどの医療診断画像、医師からの音声メモや医師と患者間の会話などの音声、さらにはMRI結果からのビデオの形式で提供されます。 また、完全に匿名化および匿名化されており、国内および国際的なデータを管理する規制の増加に伴う倫理的および財務的影響から組織を保護します。
AI開発の障害を克服する
AI開発の取り組みには、どの業界で行われていても重大な障害が含まれ、実現可能なアイデアから製品を成功させるプロセスには困難が伴います。 適切なデータを取得するという課題と、関連するすべての規制に準拠するためにデータを匿名化する必要性との間で、アルゴリズムの実際の構築とトレーニングは簡単な部分のように感じることがあります。
画期的な新しいAI開発を設計するために必要なすべての利点を組織に与えるには、Shaipのような企業との提携を検討する必要があります。 ChetanParikhとVatsalGhiyaは、米国のヘルスケアを変革する可能性のある種類のソリューションを企業が設計するのを支援するためにShaipを設立しました。顧客は説得力のあるアイデアをAIソリューションに変えることができます。
私たちのスタッフ、プロセス、およびプラットフォームが組織で機能しているので、次のXNUMXつのメリットをすぐに解き放ち、プロジェクトを成功に導くことができます。
1.データサイエンティストを解放する能力
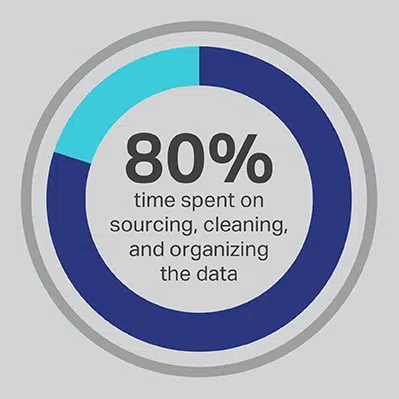
AI開発プロセスにかなりの時間がかかることを回避することはできませんが、チームが最も時間をかけて実行する機能をいつでも最適化できます。 データサイエンティストは高度なアルゴリズムと機械学習モデルの開発の専門家であるため採用しましたが、調査によると、これらのワーカーは実際にプロジェクトの原動力となるデータの調達、クリーニング、整理に80%の時間を費やしています。 データサイエンティストの76分の20以上(XNUMX%)が、これらのありふれたデータ収集プロセスも仕事の中で最も嫌いな部分であると報告していますが、高品質のデータが必要なため、実際の開発に費やす時間はわずかXNUMX%です。多くのデータサイエンティストにとって最も興味深く、知的に刺激的な仕事です。 Shaipなどのサードパーティベンダーを通じてデータを調達することで、企業は高価で才能のあるデータエンジニアにデータ管理者としての仕事をアウトソーシングさせ、代わりにAIソリューションの中で最大の価値を生み出すことができる部分に時間を費やすことができます。
2.より良い結果を達成する能力
 多くのAI開発リーダーは、費用を削減するためにオープンソースまたはクラウドソーシングのデータを使用することを決定しますが、この決定は、ほとんどの場合、長期的にはより多くの費用がかかることになります。 これらのタイプのデータはすぐに利用できますが、慎重にキュレーションされたデータセットの品質に匹敵するものではありません。 特にクラウドソーシングされたデータには、エラー、脱落、不正確さがたくさんあります。これらの問題は、開発プロセス中にエンジニアの監視の下で解決できる場合がありますが、より高いレベルから始めた場合は必要ない追加の反復が必要になります。 -最初から高品質のデータ。
多くのAI開発リーダーは、費用を削減するためにオープンソースまたはクラウドソーシングのデータを使用することを決定しますが、この決定は、ほとんどの場合、長期的にはより多くの費用がかかることになります。 これらのタイプのデータはすぐに利用できますが、慎重にキュレーションされたデータセットの品質に匹敵するものではありません。 特にクラウドソーシングされたデータには、エラー、脱落、不正確さがたくさんあります。これらの問題は、開発プロセス中にエンジニアの監視の下で解決できる場合がありますが、より高いレベルから始めた場合は必要ない追加の反復が必要になります。 -最初から高品質のデータ。
オープンソースデータに依存することは、独自の落とし穴に伴うもうXNUMXつの一般的なショートカットです。 オープンソースデータを使用してトレーニングされたアルゴリズムは、ライセンスされたデータセットに基づいて構築されたアルゴリズムよりも簡単に複製されるため、差別化の欠如は最大の問題のXNUMXつです。 このルートを使用することで、価格を引き下げ、いつでも市場シェアを獲得できる可能性のある他の参加者との競争を招くことができます。 Shaipに依存すると、熟練した管理された労働力によって集められた最高品質のデータにアクセスできます。競合他社が苦労して獲得した知的財産を簡単に再作成できないようにするカスタムデータセットの独占ライセンスを付与できます。
3.経験豊富な専門家へのアクセス
 社内の名簿に熟練したエンジニアや才能のあるデータサイエンティストが含まれている場合でも、AIツールは経験を通じてのみ得られる知恵の恩恵を受けることができます。 私たちの対象分野の専門家は、それぞれの分野で多数のAI実装を主導し、その過程で貴重な教訓を学びました。彼らの唯一の目標は、あなたがあなたの目標を達成できるよう支援することです。
社内の名簿に熟練したエンジニアや才能のあるデータサイエンティストが含まれている場合でも、AIツールは経験を通じてのみ得られる知恵の恩恵を受けることができます。 私たちの対象分野の専門家は、それぞれの分野で多数のAI実装を主導し、その過程で貴重な教訓を学びました。彼らの唯一の目標は、あなたがあなたの目標を達成できるよう支援することです。
ドメインの専門家がデータを識別、整理、分類、およびラベル付けすることで、アルゴリズムのトレーニングに使用される情報が可能な限り最高の結果を生み出すことができることがわかります。 また、定期的な品質保証を実施して、データが最高水準を満たし、ラボだけでなく実際の状況でも意図したとおりに機能することを確認します。
4.開発のタイムラインの加速
AIの開発は一夜にして行われるわけではありませんが、Shaipと提携すると、より早く行われる可能性があります。 社内のデータ収集と注釈は、残りの開発プロセスを妨げる重大な運用上のボトルネックを生み出します。 Shaipを使用すると、すぐに使用できるデータの膨大なライブラリにすぐにアクセスできます。また、専門家は、業界に関する深い知識とグローバルネットワークを使用して、必要なあらゆる種類の追加入力を入手できます。 調達や注釈の負担なしで、チームはすぐに実際の開発に取り掛かることができます。トレーニングモデルは、初期の不正確さを特定して、精度の目標を達成するために必要な反復を減らすのに役立ちます。
データ管理のすべての側面をアウトソーシングする準備ができていない場合、Shaipは、画像、ビデオ、テキスト、オーディオのサポートなど、チームがさまざまなタイプのデータをより効率的に生成、変更、および注釈付けするのに役立つクラウドベースのプラットフォームも提供します。 ShaipCloudには、ワークロードを追跡および監視する特許取得済みのソリューション、複雑で難しいオーディオ録音を転記する転記ツール、妥協のない品質を保証する品質管理コンポーネントなど、さまざまな直感的な検証およびワークフローツールが含まれています。 何よりも、スケーラブルであるため、プロジェクトのさまざまな要求が増えるにつれて成長する可能性があります。
AIイノベーションの時代はまだ始まったばかりであり、今後数年間で、業界全体を再形成したり、社会全体を変えたりする可能性のある、信じられないほどの進歩とイノベーションが見られます。 Shaipでは、専門知識を活用して変革の力として機能し、世界で最も革新的な企業がAIソリューションの力を活用して野心的な目標を達成できるよう支援したいと考えています。
私たちはヘルスケアアプリケーションと会話型AIに深い経験を持っていますが、ほぼすべての種類のアプリケーションのモデルをトレーニングするために必要なスキルも持っています。 Shaipがプロジェクトをアイデアから実装に移すのにどのように役立つかについての詳細は、当社のWebサイトで利用可能な多くのリソースを参照するか、今日私たちに連絡してください。
