コンピュータビジョンは広大なトピックであり、技術者や意欲的な起業家が短期間でそれらについて完全に知ることは不可能です。 特に、コンピュータビジョンに基づいた製品を開発していて、市場投入までの時間が限られている場合、機能的な知識を持ち、十分な情報に基づいて決定を下すには、コンピュータビジョンと画像注釈の基礎を知るための広範で実質的な何かが必要です。
このガイドでは、概念を厳選し、可能な限り簡単な方法で提示しているため、それが何であるかを明確に理解できます。 これは、製品の開発に取り掛かることができる方法、その背後にあるプロセス、関連する技術などについて明確なビジョンを持つのに役立ちます。 したがって、このガイドは、次の場合に非常に役立ちます。
概要
最近Googleレンズを使用しましたか? そうでなければ、私たち全員が待ち望んでいた未来が、その非常識な機能を探求し始めると、ついにここにあることに気付くでしょう。 Androidエコシステムのシンプルで補助的な機能であるGoogleレンズの開発は、技術の進歩と進化の面で私たちがどれだけ進んだかを証明するために続けられています。
単にデバイスを凝視し、人間から機械への一方向の通信しか経験しなかったときから、デバイスが私たちをじっと見つめ、分析し、処理することができる非線形相互作用への道を切り開きました。リアルタイム。
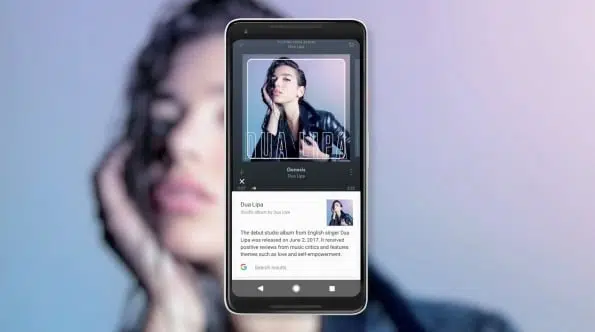
彼らはそれをコンピュータビジョンと呼んでおり、それはすべて、デバイスがカメラを通して見るものから現実世界の要素を理解し、理解することができるものについてです。 Googleレンズの素晴らしさに戻ると、ランダムなオブジェクトや製品に関する情報を見つけることができます。 デバイスのカメラをマウスまたはキーボードに向けるだけで、Googleレンズがデバイスのメーカー、モデル、メーカーを教えてくれます。
また、建物や場所をポイントして、リアルタイムで詳細を取得することもできます。 数学の問題をスキャンして解決策を見つけたり、手書きのメモをテキストに変換したり、パッケージをスキャンするだけでパッケージを追跡したり、インターフェースなしでカメラを使ってさらに多くのことを行うことができます。
コンピュータビジョンはそれだけではありません。 あなたがあなたのプロフィールに画像をアップロードしようとするとFacebookでそれを見たでしょう、そしてFacebookはあなたとあなたの友人や家族の顔を自動的に検出してタグ付けします。 コンピュータビジョンは、人々のライフスタイルを高め、複雑なタスクを簡素化し、人々の生活を楽にします。

コンピュータビジョンの画像注釈
![]() 画像アノテーションはデータラベリングのサブセットであり、画像のタグ付け、文字起こし、またはラベリングの名前でも知られています。画像のタグ付けにはバックエンドの人間が関与し、メタデータ情報と属性で画像にたゆまずタグを付けます。
画像アノテーションはデータラベリングのサブセットであり、画像のタグ付け、文字起こし、またはラベリングの名前でも知られています。画像のタグ付けにはバックエンドの人間が関与し、メタデータ情報と属性で画像にたゆまずタグを付けます。

画像分類

オブジェクトが大まかに分類される最も基本的なタイプ。 したがって、ここでは、プロセスには、車両、建物、信号機などの要素を識別するだけが含まれます。
オブジェクト検出

さまざまなオブジェクトが識別され、注釈が付けられる、もう少し具体的な関数。 車両には、車とタクシー、建物と高層ビル、車線1、2、またはそれ以上があります。
画像のセグメンテーション

これは、すべての画像の詳細になります。 これには、オブジェクトに関する情報(色、場所の外観など)を追加して、マシンを区別しやすくすることが含まれます。 たとえば、中央の車両はレーン2の黄色いタクシーになります。
オブジェクトトラッキング

これには、同じデータセット内の複数のフレームにわたる場所やその他の属性などのオブジェクトの詳細を識別することが含まれます。 ビデオや監視カメラからの映像を追跡して、オブジェクトの動きやパターンの調査を行うことができます。
バウンディングボックス

最も基本的な画像注釈手法では、専門家または注釈者がオブジェクトの周囲にボックスを描画して、オブジェクト固有の詳細を属性付けします。 この手法は、形状が対称的なオブジェクトに注釈を付けるのに最も理想的です。
バウンディングボックスのもう3つのバリエーションは、直方体です。 これらはバウンディングボックスのXNUMXDバリアントであり、通常はXNUMX次元です。 直方体は、より正確な詳細を得るために、寸法全体でオブジェクトを追跡します。 上の画像を考慮すると、車両にはバウンディングボックスを介して簡単に注釈を付けることができます。
より良いアイデアを提供するために、2Dボックスはオブジェクトの長さと幅の詳細を提供します。 ただし、直方体の手法では、オブジェクトの深さの詳細も表示されます。 直方体で画像に注釈を付けると、オブジェクトが部分的にしか表示されない場合に負担が大きくなります。 このような場合、アノテーターは既存のビジュアルと情報に基づいてオブジェクトのエッジとコーナーを概算します。
ランドマーク

この手法は、画像やフッテージ内のオブジェクトの動きの複雑さを引き出すために使用されます。 また、小さなオブジェクトを検出して注釈を付けるためにも使用できます。 ランドマークは特に 顔認識 注釈付きの顔の特徴、ジェスチャー、表情、姿勢などに。 正確な結果を得るために、顔の特徴とその属性を個別に特定する必要があります。
ランドマークが役立つ実際の例を示すために、顔の特徴や表情に基づいて帽子、ゴーグル、またはその他の面白い要素を正確に配置するInstagramまたはSnapchatフィルターについて考えてみてください。 したがって、次に犬のフィルターのポーズをとるときは、アプリが顔の特徴を目印にして正確な結果を得ていることを理解してください。
ポリゴン

画像内のオブジェクトは、常に対称的または規則的であるとは限りません。 それらが不規則または単にランダムであることがわかる場合がたくさんあります。 このような場合、アノテーターはポリゴン手法を展開して、不規則な形状やオブジェクトに正確に注釈を付けます。 この手法では、オブジェクトの寸法全体にドットを配置し、オブジェクトの円周または周囲に沿って手動で線を描画します。
ラインズ

基本的な形状やポリゴンの他に、画像内のオブジェクトに注釈を付けるために単純な線も使用されます。 この手法により、マシンはシームレスに境界を識別できます。 たとえば、自動運転車の機械の走行車線を横切って線が引かれ、操縦する必要のある境界をよりよく理解します。 ラインは、さまざまなシナリオや状況に合わせてこれらのマシンやシステムをトレーニングし、より良い運転の決定を下すのに役立ちます。




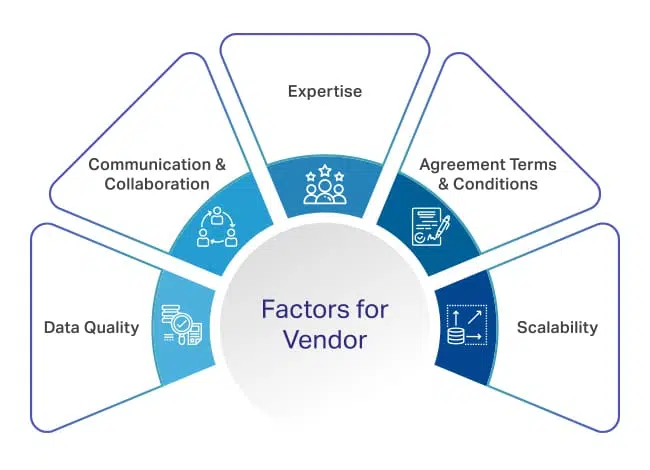
データ注釈ベンダーを選択する際に考慮すべき要素
これは大きな責任であり、機械学習モジュールの全体的なパフォーマンスは、ベンダーが提供するデータセットの品質とタイミングに依存します。 そのため、契約に署名する前に、誰と話すか、何を提供すると約束しているかにもっと注意を払い、より多くの要素を考慮する必要があります。
あなたが始めるのを助けるために、あなたが考慮しなければならないいくつかの重要な要素がここにあります。