概要
 人工知能とは、機械を使用して、日常生活を面白く冗長なタスクにすることで、人々の生活とライフスタイルを向上させることです。 AIは決して支配的な力であるとは考えられていませんが、人間と協力して信じがたいことを解決し、集団的進化への道を開く補完的な力です。
人工知能とは、機械を使用して、日常生活を面白く冗長なタスクにすることで、人々の生活とライフスタイルを向上させることです。 AIは決して支配的な力であるとは考えられていませんが、人間と協力して信じがたいことを解決し、集団的進化への道を開く補完的な力です。
現在、私たちはAIの助けを借りて、業界全体で大きなブレークスルーが起こっているという正しい道を歩んでいます。 たとえば医療を例にとると、機械学習モデルを伴うAIシステムは、専門家が癌をよりよく理解し、その治療法を考え出すのに役立ちます。 神経障害やPTSDのような懸念はAIの助けを借りて治療されています。 AIを活用した臨床試験とシミュレーションのおかげで、ワクチンは急速に開発されています。
ヘルスケアだけでなく、AIが触れるすべての業界またはセグメントに革命が起こっています。 自動運転車、スマートコンビニエンスストア、FitBitなどのウェアラブル、さらにはスマートフォンのカメラでさえ、AIを使用して顔のより良い画像をキャプチャできます。
AIの分野で起こっているイノベーションのおかげで、企業はさまざまなユースケースとソリューションでさまざまな分野に参入しています。 このため、世界のAI市場は267年末までに約2027億ドルの市場価値に達すると予想されています。さらに、世界中の企業の約37%がすでにプロセスや製品にAIソリューションを実装しています。
さらに興味深いことに、現在使用している製品とサービスの77%近くがAIを利用しています。 技術コンセプトが業種を超えて大幅に上昇している中で、企業はどのようにしてAIで不可能なことを成し遂げることができますか?

 時計のように単純なデバイスは、人間の心臓発作をどのように正確に予測しますか? 常にドライバーを必要としていた車や自動車が、突然道路でドライバーを減らすことができるのはなぜですか?
時計のように単純なデバイスは、人間の心臓発作をどのように正確に予測しますか? 常にドライバーを必要としていた車や自動車が、突然道路でドライバーを減らすことができるのはなぜですか?
チャットボットは、私たちが反対側の別の人間と話しているとどのように信じさせますか?
すべての質問に対する答えを観察すると、それはXNUMXつの要素であるDATAに要約されます。 データは、AI固有のすべての操作とプロセスの中心にあります。 これは、機械が概念を理解し、入力を処理し、正確な結果を提供するのに役立つデータです。
そこにあるすべての主要なAIソリューションは、データ収集、データ取得、またはAIトレーニングデータと呼ばれる重要なプロセスのすべての製品です。
この広範なガイドは、それが何であるか、そしてなぜそれが重要であるかを理解するのを助けることについてのすべてです。
AIデータ収集とは何ですか?
機械はそれ自身の心を持っていません。 この抽象的な概念がないため、意見、事実、推論、認知などの能力が欠けています。 それらは、スペースを占める不動のボックスまたはデバイスです。 それらを強力な媒体に変えるには、アルゴリズム、さらに重要なことにデータが必要です。
 開発されたアルゴリズムには、作業および処理するものが必要であり、その何かは、関連性があり、状況に応じた最新のデータです。 マシンが意図した目的を果たすためにそのようなデータを収集するプロセスは、AIデータ収集と呼ばれます。
開発されたアルゴリズムには、作業および処理するものが必要であり、その何かは、関連性があり、状況に応じた最新のデータです。 マシンが意図した目的を果たすためにそのようなデータを収集するプロセスは、AIデータ収集と呼ばれます。
私たちが今日使用しているすべてのAI対応製品またはソリューションとそれらが提供する結果は、長年のトレーニング、開発、および最適化から生じています。 ナビゲーションルートを提供するデバイスから、機器の故障を数日前に予測する複雑なシステムまで、すべてのエンティティは、正確に結果を提供できるようにするために、何年にもわたるAIトレーニングを受けてきました。
AIデータ収集 は、AI 開発プロセスの最初のステップであり、AI システムがどれほど効果的かつ効率的であるかを最初から決定します。 これは、無数のソースから関連するデータセットを調達するプロセスであり、AI モデルが詳細をより適切に処理し、意味のある結果を生み出すのに役立ちます。




機械学習のためにデータを収集するには?
 これは物事が少しトリッキーになり始めるところです。 最初から、現実の問題に対する解決策を念頭に置いているように見えます。AIがそれを実行するための理想的な方法であり、モデルを開発したことを知っています。 しかし今、あなたはAIトレーニングプロセスを開始する必要がある重要な段階にあります。 モデルに概念を学習させて結果を提供するには、豊富なAIトレーニングデータが必要です。 また、結果をテストしてアルゴリズムを最適化するための検証データも必要です。
これは物事が少しトリッキーになり始めるところです。 最初から、現実の問題に対する解決策を念頭に置いているように見えます。AIがそれを実行するための理想的な方法であり、モデルを開発したことを知っています。 しかし今、あなたはAIトレーニングプロセスを開始する必要がある重要な段階にあります。 モデルに概念を学習させて結果を提供するには、豊富なAIトレーニングデータが必要です。 また、結果をテストしてアルゴリズムを最適化するための検証データも必要です。
では、どのようにデータを調達しますか? どのようなデータが必要で、どれだけのデータが必要ですか? 関連データをフェッチするための複数のソースは何ですか?
企業は、MLモデルのニッチと目的を評価し、関連するデータセットを調達するための潜在的な方法を示します。 必要なデータ型を定義することで、データソーシングに関する懸念の大部分が解決されます。 より良いアイデアを提供するために、データ収集にはさまざまなチャネル、手段、ソース、または媒体があります。
悪いデータはAIの野心にどのように影響しますか?
データの収集と調達に取り組む方法がわかるという理由で、最も一般的なXNUMXつのデータリソースをリストアップしました。 ただし、この時点で、あなたの決定が常にAIソリューションの運命を決定する可能性があることも理解することが不可欠になります。
高品質のAIトレーニングデータがモデルが正確でタイムリーな結果を提供するのに役立つのと同様に、悪いトレーニングデータも、AIモデルを壊し、結果を歪め、バイアスを導入し、その他の望ましくない結果をもたらす可能性があります。
しかし、なぜこれが起こるのでしょうか? AIモデルをトレーニングおよび最適化するためのデータはありませんか? 正直なところ、違います。 これをさらに理解しましょう。
悪いデータ–それは何ですか?
 悪いデータとは、無関係、不正確、不完全、または偏ったデータです。 定義が不十分なデータ収集戦略のおかげで、ほとんどのデータ サイエンティストと 注釈の専門家 不良データの処理を余儀なくされます。
悪いデータとは、無関係、不正確、不完全、または偏ったデータです。 定義が不十分なデータ収集戦略のおかげで、ほとんどのデータ サイエンティストと 注釈の専門家 不良データの処理を余儀なくされます。
非構造化データと不良データの違いは、非構造化データの洞察がいたるところにあることです。 しかし、本質的には、それらは関係なく役立つ可能性があります。 追加の時間を費やすことにより、データサイエンティストは、非構造化データセットから関連情報を抽出することができます。 ただし、悪いデータの場合はそうではありません。 これらのデータセットには、AIプロジェクトまたはそのトレーニング目的に価値がある、または関連する洞察や情報が含まれていません。
したがって、無料のリソースからデータセットを入手したり、内部データのタッチポイントを大まかに確立したりすると、不良データをダウンロードまたは生成する可能性が高くなります。 科学者が悪いデータに取り組むとき、あなたは人間の時間を無駄にするだけでなく、あなたの製品の発売も推進しています。
悪いデータがあなたの野心に何をすることができるかについてまだ不明な場合は、ここに簡単なリストがあります:
- 悪いデータを調達するのに数え切れないほどの時間を費やし、リソースに時間、労力、お金を浪費します。
- 悪いデータは、気づかれていなければ法的な問題を引き起こし、AIの効率を低下させる可能性があります
モデル。 - 悪いデータでトレーニングされた製品をライブで使用すると、ユーザーエクスペリエンスに影響します
- 悪いデータは結果と推論にバイアスをかける可能性があり、それはさらに反発をもたらす可能性があります。
したがって、これに対する解決策があるかどうか疑問に思っている場合は、実際にあります。
AIトレーニングデータプロバイダーが救助に
 基本的な解決策のXNUMXつは、データベンダー(有料ソース)を利用することです。 AIトレーニングデータプロバイダーは、受け取るものが正確で関連性があり、構造化された形式でデータセットが提供されることを保証します。 データセットを検索するためにポータルからポータルに移動する煩わしさに関与する必要はありません。
基本的な解決策のXNUMXつは、データベンダー(有料ソース)を利用することです。 AIトレーニングデータプロバイダーは、受け取るものが正確で関連性があり、構造化された形式でデータセットが提供されることを保証します。 データセットを検索するためにポータルからポータルに移動する煩わしさに関与する必要はありません。
あなたがしなければならないのは、データを取り込んで、AIモデルを完璧にトレーニングすることだけです。 そうは言っても、次の質問は、データベンダーとのコラボレーションに伴う費用についてです。 あなた方の何人かはすでに精神的な予算に取り組んでいることを私たちは理解しています、そしてそれはまさに私たちが次に向かっているところです。
データ収集プロジェクトの効果的な予算を立てる際に考慮すべき要素
AIトレーニングは体系的なアプローチであり、それが予算編成がその不可欠な部分になる理由です。 AI開発に多額の投資を行う前に、RoI、結果の精度、トレーニング方法などの要素を検討する必要があります。 多くのプロジェクトマネージャーやビジネスオーナーは、この段階で手探りします。 彼らは急いで決定を下し、製品開発プロセスに不可逆的な変化をもたらし、最終的にはより多くの費用を費やすことを余儀なくされます。
ただし、このセクションでは正しい洞察が得られます。 AIトレーニングの予算に取り組むために座っているとき、XNUMXつのことまたは要因が避けられません。

それぞれを詳しく見ていきましょう。
必要なデータの量
AIモデルの効率と精度は、トレーニングの量に依存するとずっと言ってきました。 これは、データセットの量が多いほど、学習が増えることを意味します。 しかし、これは非常にあいまいです。 この概念に数字を付けるために、Dimensional Researchは、企業がAIモデルをトレーニングするために最低100,000のサンプルデータセットが必要であることを明らかにしたレポートを公開しました。
100,000のデータセットとは、100,000の品質と関連するデータセットを意味します。 これらのデータセットには、アルゴリズムと機械学習モデルが情報を処理し、目的のタスクを実行するために必要なすべての重要な属性、注釈、洞察が含まれている必要があります。
これは一般的な経験則であるため、必要なデータの量は、ビジネスのユースケースである別の複雑な要因にも依存することをさらに理解しましょう。 製品またはソリューションで何をしようとするかによって、必要なデータの量も決まります。 たとえば、レコメンデーションエンジンを構築している企業は、チャットボットを構築している企業とは異なるデータ量の要件があります。
データ価格戦略
実際に必要なデータ量の確定が完了したら、次にデータの価格設定戦略に取り組む必要があります。 これは、簡単に言えば、調達または生成するデータセットに対してどのように支払うかを意味します。
一般に、これらは市場で採用されている従来の価格戦略です。
| データ型 | 価格戦略 |
|---|---|
| 単一の画像ファイルごとの価格 | |
| XNUMX秒、XNUMX分、XNUMX時間、または個々のフレームあたりの価格 | |
| XNUMX秒、XNUMX分、またはXNUMX時間あたりの価格 | |
| 単語または文ごとの価格 |
ちょっと待って。 これも経験則です。 データセットを調達する実際のコストは、次のような要因にも依存します。
- データセットを入手する必要のある独自の市場セグメント、人口統計、または地理
- ユースケースの複雑さ
- どのくらいのデータが必要ですか?
- 市場投入までの時間
- カスタマイズされた要件など
観察すると、AIプロジェクトで大量の画像を取得するためのコストは低くなる可能性がありますが、仕様が多すぎると価格が高騰する可能性があります。
あなたのソーシング戦略
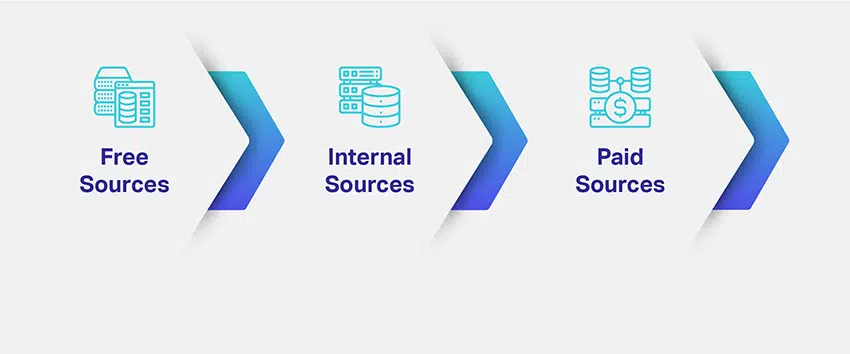
これは注意が必要です。 ご覧のとおり、AIモデルのデータを生成または取得するにはさまざまな方法があります。 常識的に言えば、必要な量のデータセットを問題なく無料でダウンロードできるため、無料のリソースが最適です。
今のところ、有料のソースは高すぎるようにも見えます。 しかし、これは複雑さの層が追加される場所です。 無料のリソースからデータセットを調達する場合、データセットをクリーンアップし、ビジネス固有の形式にコンパイルしてから、個別に注釈を付けるために、追加の時間と労力を費やします。 その過程で運用コストが発生します。
有料ソースの場合、支払いはXNUMX回限りであり、必要なときにマシン対応のデータセットを手に入れることもできます。 ここでは、費用対効果は非常に主観的です。 無料のデータセットに注釈を付けることに時間を費やす余裕があると感じた場合は、それに応じて予算を立てることができます。 また、競争が激しく、市場投入までの時間が限られていると思われる場合は、市場に波及効果をもたらす可能性があります。有料のソースを選択する必要があります。
予算編成とは、詳細を分析し、各フラグメントを明確に定義することです。 これらのXNUMXつの要素は、将来のAIトレーニングの予算編成プロセスのロードマップとして役立つはずです。
社内のデータ取得で経費を節約していますか?
 予算を立てている間、私たちは無料のリソースがあなたに長期的にもっと多くを費やすことをどのように強制するかを調査しました。 その時点で、社内のデータ取得プロセスの費用対効果について自動的に疑問に思うでしょう。
予算を立てている間、私たちは無料のリソースがあなたに長期的にもっと多くを費やすことをどのように強制するかを調査しました。 その時点で、社内のデータ取得プロセスの費用対効果について自動的に疑問に思うでしょう。
あなたがまだ有料のソースに躊躇していることを私たちは知っています、そしてそれがこのセクションがそれについてのあなたの懐疑論を取り除き、社内データ生成に伴う隠れたコストに光を当てる理由です。
社内のデータ取得は高価ですか?
はい、そうです!
さて、ここに精巧な応答があります。 費用はあなたが使うものです。 無料のリソースについて話し合っているときに、プロセスにお金、時間、労力を費やしていることを明らかにしました。 これは、社内のデータ取得にも当てはまります。
 カスタム定義のタッチ ポイントやデータ ファネルがあるからといって、 マシン対応のデータセット 最終的には。 生成するデータは、ほとんどが未加工で構造化されていません。 必要なデータはすべて XNUMX か所にあるかもしれませんが、データに含まれるものはいたるところに散らばっています。
カスタム定義のタッチ ポイントやデータ ファネルがあるからといって、 マシン対応のデータセット 最終的には。 生成するデータは、ほとんどが未加工で構造化されていません。 必要なデータはすべて XNUMX か所にあるかもしれませんが、データに含まれるものはいたるところに散らばっています。
最終的には、従業員、データサイエンティスト、アノテーター、品質保証の専門家などに支払うことになります。 また、注釈ツールと
CMS、CRM、およびその他のインフラストラクチャ費用の保守。
さらに、データセットにはバイアスと精度の問題があり、手動で並べ替える必要があります。 また、AIトレーニングデータチームに離職の問題がある場合は、新しいメンバーの募集、プロセスへの方向付け、ツールを使用するためのトレーニングなどに費やす必要があります。
最終的には、長期的に見た場合よりも多くの費用を費やすことになります。 注釈費用もあります。 任意の時点で、社内データを処理するために発生する総コストは次のとおりです。
発生したコスト=アノテーターの数*アノテーターあたりのコスト+プラットフォームのコスト
AIトレーニングカレンダーが数か月に予定されている場合は、一貫して発生する費用を想像してください。 それで、これはデータ取得の懸念に対する理想的な解決策ですか、それとも代替手段はありますか?
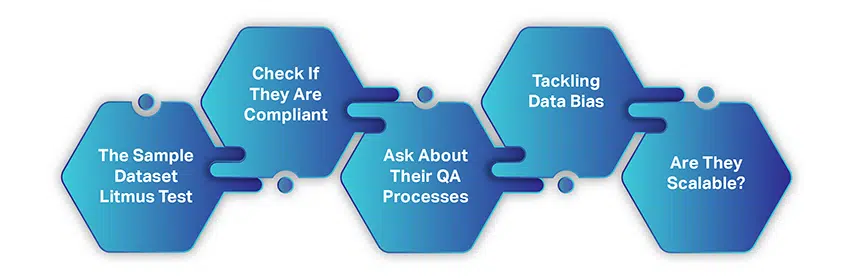
適切なAIデータ収集会社を選択する方法
AIデータ収集会社の選択は、無料のリソースからデータを収集するほど複雑でも時間もかかりません。 考慮し、コラボレーションのために握手する必要がある単純な要素はごくわずかです。
あなたがデータベンダーを探し始めているとき、私たちはあなたがこれまでに議論したことを何でもフォローして検討したと仮定します。 ただし、ここに簡単な要約があります。
- 明確に定義されたユースケースを念頭に置いています
- 市場セグメントとデータ要件が明確に確立されている
- あなたの予算は適切です
- そして、あなたはあなたが必要とするデータの量についての考えを持っています
これらの項目をオフにして、理想的なトレーニングデータサービスプロバイダーを探す方法を理解しましょう。