


会話型AIとは
会話型 AI は、人工知能の高度な形式であり、マシンがユーザーと人間のようなインタラクティブな対話を行うことを可能にします。 この技術は、人間の言葉を理解して解釈し、自然な会話をシミュレートします。 時間の経過に伴うやり取りから学習して、状況に応じて対応できます。
会話型 AI システムは、チャットボット、音声アシスタント、カスタマー サポート プラットフォームなどのアプリケーションで、デジタルおよび通信チャネル全体で広く使用されています。
会話型 AI 市場は、近年急速に成長しています。 当初は娯楽目的で開発された会話型 AI は、デジタル エコシステムの不可欠な部分になりました。 その影響を示す重要な統計を次に示します。
- 世界の会話型 AI 市場は 6.8 年に 2021 億ドルと評価され、18.4 年までに 2026% の CAGR で 22.6 億ドルに成長すると予測されています。 2028 年までに、市場規模は 2022年の174億4000万ドル.
- その普及にもかかわらず、 視聴者の38%が 日常生活で AI を使用していることに気付いていないユーザーの割合。
- A ガートナー調査 多くの企業がチャットボットを主要な AI アプリケーションとして認識しており、ホワイトカラー ワーカーの 70% 近くが 2022 年までに日常的に会話型プラットフォームを操作するようになると予想されていることがわかりました。
- パンデミック以降、会話型エージェントが処理するインタラクションの量は、 視聴者の38%が 複数の業界にわたって。
- 世界中のデジタル マーケティングに AI を使用するマーケターの割合は、29 年の 2018% から 84中2020%.
- 2022年には、 視聴者の38%が の大人の音声アシスタント ユーザーが、スマートフォンで会話型 AI テクノロジーを使用しました。
- 製品の閲覧と検索は、 トップショッピング活動 2021 年の調査で、米国のユーザーを対象に音声アシスタント テクノロジーを使用して実施されました。
- 世界中の技術専門家の間で、ほぼ 視聴者の38%が 顧客サービスに仮想アシスタントを使用します。
- 2024 年までに、北米のカスタマー サービスの意思決定者の 73% が、オンライン チャット、ビデオ チャット、チャットボット、またはソーシャル メディアが、 最も利用されているカスタマー サービス チャネル.
- 2021年の調査では、 視聴者の38%が の米国の幹部は、AI が自社内の「主流技術」になることに同意しています。
- 2022年XNUMX月現在、 視聴者の38%が 昨年、顧客サービスのために AI チャットボットと通信した米国の成人の割合。
- 2022年には、 3.5億 チャットボット アプリは世界中でアクセスされました。
- 上位 XNUMX つの理由 米国の消費者は、営業時間 (18%)、製品情報 (17%)、カスタマー サービス リクエスト (16%) にチャットボットを使用しています。
これらの統計は、さまざまな業界や消費者行動において会話型 AI の採用と影響力が高まっていることを浮き彫りにしています。
会話型 AI の仕組み
会話型 AI は、自然言語処理 (NLP) やその他の高度なアルゴリズムを使用して、コンテキストに富んだ対話を行います。 AI がより広い範囲のユーザー入力に遭遇するにつれて、パターン認識と予測能力が向上します。 会話型 AI がユーザーと関わるプロセスは、次の XNUMX つの主要なステップに分けることができます。

ステップ 1: 入力コレクション – ユーザーは、テキストまたは音声で入力を提供します。
ステップ 2: 入力処理 – 入力がテキスト形式の場合、自然言語理解 (NLU) を使用して単語から意味を抽出します。 音声入力の場合、まず自動音声認識 (ASR) を使用して、音声をさらに分析できる言語トークンに変換します。
ステップ 3: 応答の生成 – 自然言語生成技術を利用して、ユーザーの問い合わせに適切に対応します。
ステップ 4: 継続的な改善 – 会話型 AI システムは、ユーザー入力を経時的に分析し、応答を改良して正確性と関連性を確保します。



会話型AIにおける一般的なデータの課題を軽減する
会話型AIは、人間とコンピューターのコミュニケーションを動的に変革しています。 また、多くの企業は、ビジネスのやり方を変えることができる高度な会話型AIツールとアプリケーションの開発に熱心です。 ただし、あなたとあなたの顧客との間のより良いコミュニケーションを促進することができるチャットボットを開発する前に、あなたはあなたが直面するかもしれない多くの発達上の落とし穴を見る必要があります。
言語の多様性
 複数の言語に対応できるチャットアシスタントを開発することは困難です。 さらに、グローバル言語の多様性により、すべての顧客にシームレスに顧客サービスを提供するチャットボットを開発することは困難です。
複数の言語に対応できるチャットアシスタントを開発することは困難です。 さらに、グローバル言語の多様性により、すべての顧客にシームレスに顧客サービスを提供するチャットボットを開発することは困難です。
2022年には、 約1.5億 人々は世界中で英語を話し、続いて1.1億人の話者がいる中国語を話しました。 英語は世界で最も話され、勉強されている外国語ですが、 視聴者の38%が 世界人口のそれを話します。 これにより、残りの世界人口(80%)は英語以外の言語を話すようになります。 したがって、チャットボットを開発するときは、言語の多様性も考慮する必要があります。
言語の変動性
人間は異なる言語と同じ言語を異なる方法で話します。 残念ながら、感情、方言、発音、アクセント、ニュアンスを考慮に入れて、機械が話し言葉の変動性を完全に理解することはまだ不可能です。
私たちの言葉と言語の選択は、私たちがタイプする方法にも反映されています。 マシンは、アノテーターのグループがさまざまな音声データセットでトレーニングする場合にのみ、言語の多様性を理解して評価することが期待できます。
スピーチのダイナミズム
会話型 AI の開発におけるもう XNUMX つの大きな課題は、音声のダイナミズムを争いに持ち込むことです。 たとえば、私たちは会話するときにいくつかのつなぎ言葉、ポーズ、文の断片、解読不能な音声を使用します。 さらに、私たちは通常、すべての単語の間に一時停止したり、正しい音節を強調したりすることがないため、音声は書き言葉よりもはるかに複雑です。
私たちが他の人の話を聞くとき、私たちは私たちの生涯の経験を使って彼らの会話の意図と意味を引き出す傾向があります。 その結果、あいまいな場合でも、彼らの言葉を文脈化して理解します。 ただし、マシンはこの品質を実現できません。
ノイズの多いデータ
ノイズの多いデータやバックグラウンドノイズは、ドアベル、犬、子供、その他のバックグラウンドサウンドなど、会話に価値をもたらさないデータです。 したがって、スクラブまたはフィルタリングすることが不可欠です オーディオファイル これらの音を分析し、AIシステムをトレーニングして、重要な音と重要でない音を識別します。
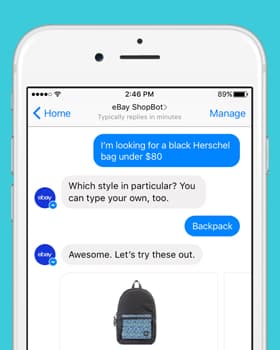
さまざまな音声データタイプの長所と短所
 AI を活用した音声認識システムや会話型 AI を構築するには、大量のトレーニングとテストのデータセットが必要です。 ただし、信頼性が高く、特定のプロジェクトのニーズを満たす、このような高品質のデータセットにアクセスすることは簡単ではありません。 ただし、トレーニング データセットを探している企業が利用できるオプションはありますが、それぞれのオプションには長所と短所があります。
AI を活用した音声認識システムや会話型 AI を構築するには、大量のトレーニングとテストのデータセットが必要です。 ただし、信頼性が高く、特定のプロジェクトのニーズを満たす、このような高品質のデータセットにアクセスすることは簡単ではありません。 ただし、トレーニング データセットを探している企業が利用できるオプションはありますが、それぞれのオプションには長所と短所があります。
一般的なデータセットタイプを探している場合は、多くの人前で話すオプションを利用できます。 ただし、プロジェクト要件により具体的で関連性のあるものについては、自分で収集してカスタマイズする必要がある場合があります。
独自の音声データ
最初に確認する場所は、会社の専有データです。 ただし、顧客の音声データを使用する法的権利と同意があるため、この大規模なデータセットをプロジェクトのトレーニングとテストに使用できる可能性があります。
長所:
- 追加のトレーニングデータ収集コストはありません
- トレーニングデータはおそらくあなたのビジネスに関連しています
- 音声データには、自然環境の背景音響、動的ユーザー、およびデバイスも含まれます。
短所:
- このようなデータを使用すると、記録および使用の許可に多額の費用がかかる可能性があります。
- 音声データには、言語、人口統計、または顧客ベースの制限がある可能性があります
- データは無料の場合がありますが、処理、文字起こし、タグ付けなどの費用は引き続きかかります。
公開データセット
人前で話すデータセットは、自分のデータセットを使用する予定がない場合のもうXNUMXつのオプションです。 これらのデータセットはパブリックドメインの一部であり、オープンソースプロジェクト用に収集できます。
メリット:
- 公開データセットは無料で、低予算のプロジェクトに最適です
- それらはすぐにダウンロードできます
- 公開データセットには、スクリプト化されたサンプルセットとスクリプト化されていないサンプルセットがあります。
デメリット:
- 処理と品質保証のコストが高くなる可能性があります
- 人前で話すデータセットの品質は大幅に異なります
- 提供される音声サンプルは通常一般的なものであるため、特定の音声プロジェクトの開発には適していません。
- データセットは通常、英語に偏っています
事前にパッケージ化された/既製のデータセット
公開データまたは独自仕様の場合は、事前にパッケージ化されたデータセットを探索することもできます。 音声データ収集 あなたのニーズに合いません。
ベンダーは、クライアントに再販するという特定の目的のために、事前にパッケージ化された音声データセットを収集しました。 このタイプのデータセットは、一般的なアプリケーションや特定の目的を開発するために使用できます。
メリット:
- 特定の音声データのニーズに合ったデータセットにアクセスできる場合があります
- 独自のデータセットを収集するよりも、事前にパッケージ化されたデータセットを使用する方が手頃です
- データセットにすばやくアクセスできる可能性があります
デメリット:
- データセットは事前にパッケージ化されているため、プロジェクトのニーズに合わせてカスタマイズされていません。
- さらに、データセットは他の企業が購入できるため、会社に固有のものではありません。
カスタム収集データセットを選択します
音声アプリケーションを作成するときは、特定の要件をすべて満たすトレーニングデータセットが必要になります。 ただし、プロジェクトの固有の要件に対応する、事前にパッケージ化されたデータセットにアクセスできる可能性はほとんどありません。 利用可能な唯一のオプションは、データセットを作成するか、サードパーティのソリューションプロバイダーを通じてデータセットを調達することです。
トレーニングとテストのニーズに対応するデータセットは完全にカスタマイズ可能です。 言語のダイナミズム、音声データの多様性、およびさまざまな参加者へのアクセスを含めることができます。 さらに、データセットは、プロジェクトの要求に合わせて時間どおりにスケーリングできます。
メリット:
- データセットは、特定のユースケース用に収集されます。 AIアルゴリズムが意図した結果から逸脱する可能性は最小限に抑えられます。
- AIデータのバイアスを制御および削減する
デメリット:
- データセットにはコストと時間がかかる場合があります。 ただし、メリットは常にコストを上回ります。

会話型AIを使用する業界
現在、会話型AIは主にチャットボットとして使用されています。 ただし、いくつかの業界では、このテクノロジーを実装して大きなメリットを獲得しています。 会話型AIを使用している業界のいくつかは次のとおりです。
ヘルスケア
 会話型AIは、ヘルスケアセクターに大きな影響を与えています。 会話型AIは、患者、医師、スタッフ、看護師、その他の医療関係者にとって有益であることが証明されています。
会話型AIは、ヘルスケアセクターに大きな影響を与えています。 会話型AIは、患者、医師、スタッフ、看護師、その他の医療関係者にとって有益であることが証明されています。
いくつかの利点は次のとおりです
- 治療後の段階での患者の関与
- 予定スケジュールチャットボット
- よくある質問や一般的な質問への回答
- 症状の評価
- 救命救急患者を特定する
- 緊急事態のエスカレーション
eコマース
 会話型AIは、eコマースビジネスが顧客と関わり、カスタマイズされた推奨事項を提供し、製品を販売するのを支援しています。
会話型AIは、eコマースビジネスが顧客と関わり、カスタマイズされた推奨事項を提供し、製品を販売するのを支援しています。
eコマース業界は、このクラス最高のテクノロジーのメリットを活用しています。
- 顧客情報の収集
- 関連する製品情報と推奨事項を提供する
- 顧客満足度の向上
- 注文と返品の支援
- よくある質問への回答
- クロスセルおよびアップセル製品
バンキング
 銀行セクターは、会話型AIツールを導入して、顧客とのやり取りを強化し、要求をリアルタイムで処理し、複数のチャネルにわたって簡素化された統一された顧客体験を提供しています。
銀行セクターは、会話型AIツールを導入して、顧客とのやり取りを強化し、要求をリアルタイムで処理し、複数のチャネルにわたって簡素化された統一された顧客体験を提供しています。
- 顧客がリアルタイムで残高を確認できるようにする
- 預金を手伝う
- 税金の申告とローンの申し込みを支援します
- 請求書のリマインダー、通知、アラートを送信することにより、銀行業務プロセスを合理化します
保険
 銀行セクターと同様に、保険業界も会話型AIによってデジタル的に推進されており、そのメリットを享受しています。 たとえば、会話型AIは、保険業界が紛争や請求を解決するためのより迅速で信頼性の高い手段を提供するのに役立ちます。
銀行セクターと同様に、保険業界も会話型AIによってデジタル的に推進されており、そのメリットを享受しています。 たとえば、会話型AIは、保険業界が紛争や請求を解決するためのより迅速で信頼性の高い手段を提供するのに役立ちます。
- ポリシーの推奨事項を提供する
- より迅速な請求の解決
- 待ち時間をなくす
- 顧客からのフィードバックとレビューを収集する
- ポリシーに関する顧客の認識を高める
- より迅速な請求と更新を管理する

Shaipオファリング
高度なヒューマン マシン インタラクション音声アプリケーションを開発するための高品質で信頼性の高いデータセットの提供に関して、Shaip は導入の成功により市場をリードしてきました。 しかし、チャットボットや音声アシスタントの深刻な不足により、企業は AI プロジェクトのトレーニングとテスト用にカスタマイズされた正確で高品質なデータセットを提供する市場リーダーである Shaip のサービスをますます求めています。
自然言語処理を組み合わせることで、人間の会話を効果的に模倣する正確な音声アプリケーションの開発を支援することで、パーソナライズされたエクスペリエンスを提供できます。 私たちは、高品質の顧客体験を提供するために、多数のハイエンドテクノロジーを使用しています。 NLPは、人間の言語を解釈し、人間と対話するための機械を教えています。
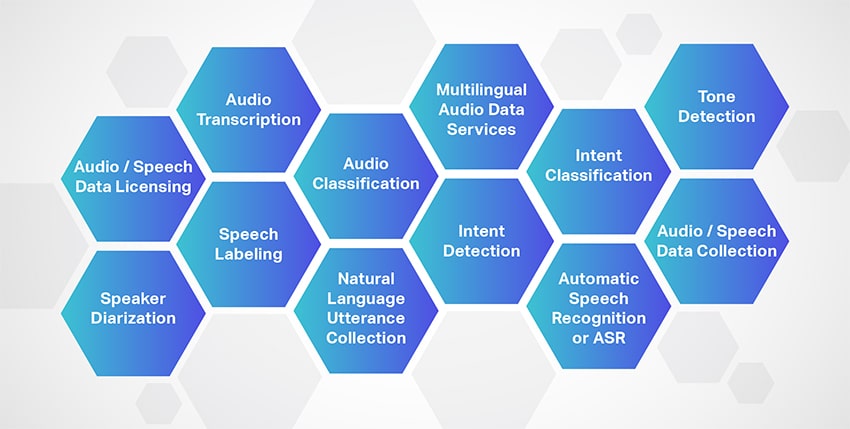
音声文字変換
Shaipは、あらゆるタイプのプロジェクトにさまざまな音声/音声ファイルを提供する主要な音声文字変換サービスプロバイダーです。 さらに、Shaipは、インタビュー、セミナー、レクチャー、ポッドキャストなどのオーディオおよびビデオファイルを読みやすいテキストに変換するための100%人間が生成した文字起こしサービスを提供します。
音声ラベリング
Shaip は、オーディオ ファイル内のサウンドと音声を専門的に分離し、各ファイルにラベルを付けることにより、広範な音声ラベル付けサービスを提供します。 類似した音声を正確に分離し、注釈を付けることで、
スピーカーのダイアリゼーション
シャープの専門知識は、ソースに基づいてオーディオ録音をセグメント化することにより、優れた話者ダイアライゼーション ソリューションを提供することにまで及びます。 さらに、話者の数を決定するために、話者 1、話者 2、音楽、背景雑音、車両音、沈黙などの話者の境界が正確に識別および分類されます。
オーディオ分類
注釈は、オーディオファイルを所定のカテゴリに分類することから始まります。 カテゴリは主にプロジェクトの要件に依存し、通常、ユーザーの意図、言語、セマンティックセグメンテーション、バックグラウンドノイズ、話者の総数などが含まれます。
自然言語発話集/目覚めの言葉
質問をしたり、要求を開始したりするときに、クライアントが常に類似した単語を選択することを予測することは困難です。 例:「最寄りのレストランはどこですか?」 「近くのレストランを探す」または「近くにレストランはありますか?」
XNUMXつの発話はすべて同じ意図を持っていますが、言い回しが異なります。 順列と組み合わせを通じて、Shaipの専門家の会話型AIスペシャリストは、同じ要求を明確にするために可能なすべての組み合わせを特定します。 Shaipは、セマンティクス、コンテキスト、トーン、ディクション、タイミング、ストレス、方言に焦点を当てて、発話とウェイクアップワードを収集して注釈を付けます。
多言語オーディオデータサービス
多言語音声データ サービスは、Shaip が提供するもう 150 つの非常に好まれるサービスです。当社には、世界中の XNUMX 以上の言語と方言で音声データを収集するデータ コレクター チームがいます。
インテント検出
人間の相互作用とコミュニケーションは、私たちが彼らに認めるよりも複雑であることがよくあります。 そして、この生来の複雑さは、人間の発話を正確に理解するためにMLモデルを訓練することを困難にします。
さらに、同じ人口統計または異なる人口統計グループの異なる人々は、同じ意図または感情を異なる方法で表現することができます。 したがって、音声認識システムは、人口統計に関係なく、共通の意図を認識するようにトレーニングする必要があります。
一流のMLモデルをトレーニングおよび開発できるようにするために、スピーチセラピストは、システムが人間が同じ意図を表現するいくつかの方法を特定するのに役立つ、広範で多様なデータセットを提供します。
意図の分類
さまざまな人から同じ意図を特定するのと同様に、チャットボットも、顧客のコメントをさまざまなカテゴリに分類するようにトレーニングする必要があります。これは、事前に決定されたものです。 すべてのチャットボットまたは仮想アシスタントは、特定の目的で設計および開発されています。 Shaipは、必要に応じてユーザーの意図を事前定義されたカテゴリに分類できます。
自動音声認識またはASR
音声認識」とは、話し言葉をテキストに変換することを指します。 ただし、音声認識と話者識別は、話されたコンテンツと話者のIDの両方を識別することを目的としています。 ASRの精度は、スピーカーの音量、バックグラウンドノイズ、録音機器などのさまざまなパラメーターによって決まります。
トーン検出
人間の相互作用のもうXNUMXつの興味深い側面は、トーンです。単語の意味は、発声されるトーンに応じて本質的に認識されます。 私たちが言うことは重要ですが、それらの言葉をどのように言うかによっても意味が伝わります。
たとえば、「WhatJoy!」などの簡単なフレーズ。 幸福の叫びである可能性があり、皮肉であることが意図されている可能性もあります。 それはトーンとストレスに依存します。
'何してるの?'
'何してるの?'
これらの文には両方とも正確な単語が含まれていますが、単語の強弱が異なるため、文全体の意味が変わります。 チャットボットは、幸福、皮肉、怒り、イライラなどの表現を識別するように訓練されています。 ここでシャープの言語聴覚士とアノテーターの専門知識が活かされます。
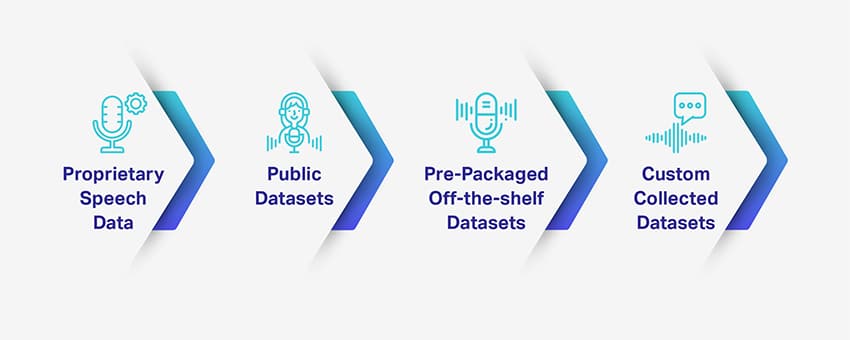
音声/音声データのライセンス
Shaipは、プロジェクトの特定のニーズに合わせてカスタマイズできる、比類のない高品質の音声データセットを提供します。 ほとんどのデータセットはすべての予算に収まり、データは将来のすべてのプロジェクトの需要を満たすためにスケーラブルです。 40以上の言語で、100以上の方言で50k時間以上の既成の音声データセットを提供しています。 また、自発的、独白、台本、目覚めの言葉など、さまざまな種類の音声を提供しています。 全体を見る データカタログ。
音声/音声データ収集
質の高い音声データセットが不足している場合、結果として得られる音声ソリューションには問題が山積し、信頼性が失われる可能性があります。 Shaipは、多言語の音声コレクション、音声文字変換、および 注釈ツール プロジェクト用に完全にカスタマイズ可能なサービス。
音声データは、一方の端の自然な音声からもう一方の端の不自然な音声まで、スペクトルとして表示できます。 自然なスピーチでは、話し手が自発的に会話するように話します。 一方、話者が台本を読み上げているため、不自然な発話は制限されます。 最後に、話者は、スペクトルの中央で制御された方法で単語やフレーズを発声するように促されます。
シャープの専門知識は、150 以上の言語でさまざまな種類の音声データセットを提供することにまで及びます。

































導入事例
私たちはいくつかのトップ企業やブランドと協力し、最高位の会話型AIソリューションを提供してきました。
私たちのサクセスストーリーのいくつかは次のとおりです。
- ライブチャットボットをトレーニングおよび構築するために、10,000時間以上の多言語の文字起こし、会話、音声ファイルを含む音声認識データセットを開発しました。
- 保険チャットボットのトレーニングに使用される、会話ごとに1000ターンの数千の会話の高品質データセットを構築しました。
- 3000人以上の言語専門家からなるチームは、デジタルアシスタントのトレーニングとテストのために、1000の母国語で27時間以上の音声ファイルとトランスクリプトを提供しました。
- アノテーターと言語学の専門家のチームも、20,000を超えるグローバル言語で27時間以上の発話を迅速に収集し、配信しました。
- 当社の自動音声認識サービスは、業界で最も好まれているサービスのXNUMXつです。 信頼性の高いラベルの付いたオーディオファイルを提供し、ASRモデルの信頼性を向上させるために、さまざまなスピーカーセットからの幅広い文字起こしと辞書を使用して、発音、トーン、意図に特別な注意を払っています。
私たちのサクセスストーリーは、常に最新のテクノロジーを使用して最高のサービスをクライアントに提供するという私たちのチームのコミットメントに端を発しています。 私たちの違いは、私たちの仕事が、ゴールドスタンダードの注釈の公平で正確なデータセットを提供する専門家の注釈者によって支えられていることです。
30,000人を超える貢献者からなるデータ収集チームは、MLモデルの迅速な展開を支援する高品質のデータセットを調達、スケーリング、提供できます。 さらに、最新のAIベースのプラットフォームに取り組んでおり、最も近い競合他社よりもはるかに高速に高速音声データソリューションをビジネスに提供することができます。
