



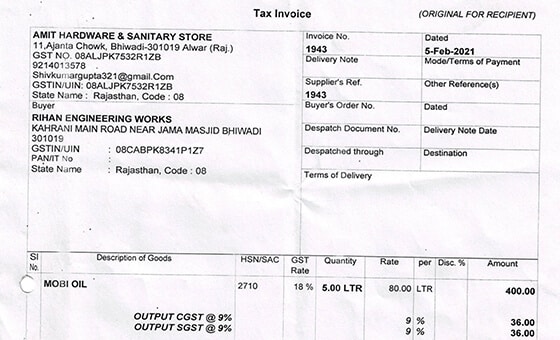

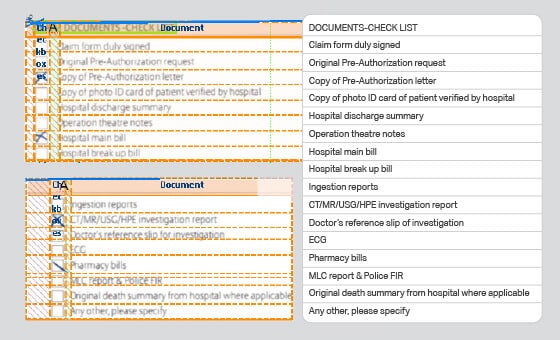





- 使用事例: 物体認識モデル
- フォーマット: 動画
- ボリューム: 5,000+
- 注釈: いいえ

- 使用事例: Doc。 認識モデル
- フォーマット: 画像
- ボリューム: 15,900+
- 注釈: いいえ
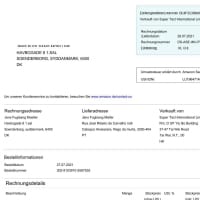
- 使用事例: 請求書の記録。 モデル
- フォーマット: 画像
- ボリューム: 45,000+
- 注釈: いいえ

- 使用事例: いいえ。プレート認識
- フォーマット: 画像
- ボリューム: 3,500+
- 注釈: いいえ

- 使用事例: OCRモデル
- フォーマット: 画像
- ボリューム: 90,000+
- 注釈: 有り

- 使用事例: 多言語OCRモデル
- フォーマット: 画像
- ボリューム: 23,500+
- 注釈: 有り
- 使用事例: 物体検出モデル
- フォーマット: 画像
- ボリューム: 11,500+
- 注釈: いいえ

- 使用事例: AIモデルを受け取る
- フォーマット: 画像
- ボリューム: 75,000+
- 注釈: いいえ

のワークプ
専任の訓練を受けたチーム:
- データ収集、ラベリング、QAのための30,000人以上の協力者
- 資格のあるプロジェクト管理チーム
- 経験豊富な製品開発チーム
- タレントプールソーシング&オンボーディングチーム

プロセス
最高のプロセス効率が保証されます:
- 堅牢な6シックスシグマステージゲートプロセス
- シックスシグマ黒帯の専任チーム–主要なプロセス所有者と品質コンプライアンス
- 継続的改善とフィードバックループ

プラットフォーム
特許取得済みのプラットフォームには次のような利点があります。
- Webベースのエンドツーエンドプラットフォーム
- 非の打ちどころのない品質
- より速いTAT
- シームレスな配信



臨床NLPの作成は重要なタスクであり、解決するには膨大なドメインの専門知識が必要です。 この分野では、あなたがGoogleより数年進んでいることがはっきりとわかります。 私はあなたと一緒に働き、あなたをスケーリングしたいと思います。
グーグル株式会社 取締役
私のエンジニアリングチームは、ヘルスケア音声APIの開発中にShaipのチームと2年以上協力しました。 私たちは、ヘルスケア固有のNLPで行われた彼らの仕事と、複雑なデータセットで達成できることに感銘を受けました。
グーグル株式会社 エンジニアリング責任者