インターネットは、人々が世界中のあらゆることについて自由に意見、見解、提案を表明するための扉を開きました。 ソーシャルメディア、ウェブサイト、ブログ。 人々 (顧客) は、自分の意見を表明するだけでなく、他の人の購入決定にも影響を与えています。 ネガティブであろうとポジティブであろうと、センチメントは、製品やサービスの販売を懸念するビジネスやブランドにとって重要です。
ビジネスで使用するために企業がコメントをマイニングするのを支援することは、 自然言語処理. XNUMX社にXNUMX社 は、ビジネス上の意思決定を強化するために、来年中に NLP テクノロジーを実装する計画を立てています。 NLP は、感情分析を使用して、企業が未加工の非構造化データから解釈可能な洞察を導き出すのに役立ちます。
オピニオンマイニングや 感情分析 正確な感情を識別するために使用される NLP の手法です。 ポジティブ、ネガティブ、またはニュートラル – コメントとフィードバックに関連付けられています。 NLP の助けを借りて、コメント内のキーワードが分析され、キーワードに含まれる肯定的な単語または否定的な単語が判別されます。
感情は、テキストの一部の感情に感情スコアを割り当てる (テキストを肯定的または否定的に決定する) スケーリング システムで採点されます。
多言語感情分析とは

名前が示すように、 多言語感情分析 は、複数の言語のセンチメント スコアを実行する手法です。 しかし、それはそれほど単純ではありません。 私たちの文化、言語、経験は、購買行動や感情に大きな影響を与えます。 ユーザーの言語、文脈、文化をよく理解していないと、ユーザーの意図、感情、解釈を正確に理解することはできません。
自動化は現代の問題の多くに対する答えですが、 機械翻訳 ソフトウェアは、コメント内の言語のニュアンス、口語表現、機微、および文化的参照を取得できません。 商品のレビュー それは翻訳しています。 ML ツールは翻訳を提供する場合がありますが、役に立たない場合があります。 これが、多言語感情分析が必要な理由です。
多言語感情分析が必要な理由
ほとんどの企業はコミュニケーション手段として英語を使用していますが、世界中のほとんどの消費者は英語を使用していません。
Ethnologue によると、世界人口の約 13% が英語を話します。 さらに、ブリティッシュ・カウンシルは、世界人口の約 25% が英語を十分に理解していると述べています。 これらの数字が信じられるとすれば、大部分の消費者は英語以外の言語で相互にやり取りし、ビジネスとやり取りします。
ビジネスの主な目的が、顧客ベースを維持し、新しい顧客を引き付けることである場合、ビジネスは顧客の意見を詳細に理解する必要があります。 母国語. 各コメントを手動で確認したり、英語に翻訳したりするのは面倒なプロセスであり、効果的な結果は得られません。
持続可能な解決策は、多言語を開発することです 感情分析システム ソーシャル メディア、フォーラム、アンケートなどで顧客の意見、感情、提案を検出して分析します。
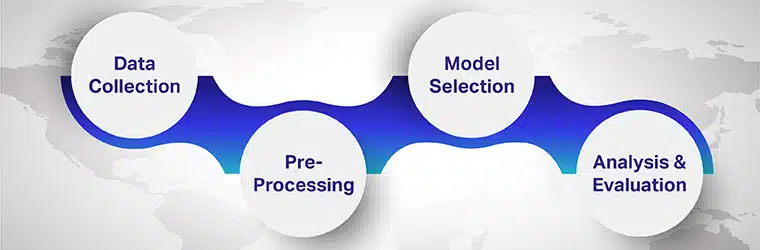
多言語感情分析の実行手順
単一言語かどうかに関係なく、センチメント分析 複数の言語、抽出するために機械学習モデル、自然言語処理、およびデータ分析技術の適用を必要とするプロセスです 多言語センチメント スコアリング データから。
多言語感情分析に含まれる手順は次のとおりです。
ステップ 1: データの収集
データの収集は、感情分析を適用するための最初のステップです。 多言語を作成するには 感情分析モデル、さまざまな言語でデータを取得することが重要です。 すべては、収集、注釈、およびラベル付けされたデータの品質に依存します。 API、オープンソース リポジトリ、およびパブリッシャーからデータを取得できます。
ステップ 2: 前処理
収集された Web データはクリーンアップされ、そこから情報が収集されます。 「the」「is」など、特定の意味を伝えないテキストの部分は削除する必要があります。 さらに、テキストは単語グループにグループ化して、肯定的または否定的な意味を伝えるために分類する必要があります。
分類の品質を向上させるには、コンテンツから HTML タグ、広告、スクリプトなどのノイズを除去する必要があります。 人々が使用する言語、語彙、文法は、ソーシャル ネットワークによって異なります。 そのようなコンテンツを正規化し、前処理のために準備することが重要です。
前処理のもう XNUMX つの重要なステップは、自然言語処理を使用して文を分割し、ストップ ワードを削除し、品詞にタグを付け、単語を原形に変換し、単語を記号とテキストにトークン化することです。
ステップ 3: モデルの選択
ルールベースのモデル: 多言語意味分析の最も単純な方法は、ルールベースです。 ルールベースのアルゴリズムは、専門家によってプログラムされた一連の事前定義されたルールに基づいて分析を実行します。
ルールは、肯定的または否定的な語句を指定できます。 たとえば、製品やサービスのレビューを取り上げると、「すばらしい」、「遅い」、「待っている」、「役立つ」などの肯定的または否定的な言葉が含まれている可能性があります。 この方法では、単語を簡単に分類できますが、複雑な単語や頻度の低い単語を誤分類する可能性があります。
自動モデル: 自動モデルは、人間のモデレーターが関与することなく、多言語の感情分析を実行します。 機械学習モデルは人間の努力によって構築されますが、開発後は自動的に機能して正確な結果を提供できます。
テスト データが分析され、各コメントが手動で肯定的または否定的に分類されます。 次に、ML モデルは、新しいテキストを既存のコメントと比較して分類することにより、テスト データから学習します。
ステップ 4: 分析と評価
ルールベースの機械学習モデルは、時間と経験を重ねて改善および強化できます。 使用頻度の低い単語のレキシコンまたは多言語感情のライブ スコアを更新して、分類をより迅速かつ正確に行うことができます。
翻訳の挑戦
翻訳だけじゃ物足りない? 実は違う!
翻訳には、ある言語からテキストまたはテキストのグループを転送し、別の言語で同等のものを見つけることが含まれます。 しかし、翻訳は単純でも効果的でもありません。
それは、人間が自分のニーズを伝えるだけでなく、自分の感情を表現するために言語を使用するためです。 さらに、英語、ヒンディー語、マンダリン、タイ語など、言語ごとに大きな違いがあります。 この文学的なミックスに、感情、スラング、イディオム、皮肉、絵文字を追加します。 テキストの正確な翻訳を取得することはできません。
主な課題のいくつか 機械翻訳
- 主観
- コンテキスト
- スラングとイディオム
- 皮肉
- 比較
- 中立
- 絵文字と現代の言葉の使い方。
商品、価格、サービス、機能、品質に関する口コミやコメント、コミュニケーションの意図を正確に理解できなければ、企業は顧客のニーズや意見を理解することができません。
多言語の感情分析は困難なプロセスです。 各言語には、独自の語彙、構文、形態、および音韻論があります。 これに文化、俗語、 感情表現、皮肉、および調性、そして効率的な AI を活用した ML ソリューションを必要とする挑戦的なパズルを手に入れました。
堅牢な多言語を開発するには、包括的な多言語データセットが必要です 感情分析ツール レビューを処理し、ビジネスに強力な洞察を提供できます。 Shaip は、効率的で正確な開発を支援する、業界向けにカスタマイズされ、ラベル付けされ、注釈が付けられたデータセットを複数の言語で提供するマーケット リーダーです。 多言語感情分析ソリューション.