
人工知能は音楽業界に革命をもたらし、自動作曲、マスタリング、パフォーマンス ツールを提供します。 AI アルゴリズムは、斬新な楽曲を生成し、ヒットを予測し、リスナーのエクスペリエンスをパーソナライズして、音楽の制作、流通、消費を変革します。 この新たなテクノロジーは、エキサイティングな機会と困難な倫理的ジレンマの両方をもたらします。
作曲家が交響曲を書くには音符が必要であるのと同様に、機械学習 (ML) モデルが効果的に機能するにはトレーニング データが必要です。 メロディー、リズム、感情が絡み合う音楽の世界では、高品質のトレーニング データの重要性はどれだけ強調してもしすぎることはありません。 これは、予測分析、ジャンル分類、または自動文字起こしのための堅牢で正確な音楽 ML モデルを開発するためのバックボーンです。
ML モデルの生命線であるデータ
機械学習は本質的にデータ駆動型です。 これらの計算モデルはデータからパターンを学習し、予測や意思決定を可能にします。 音楽 ML モデルの場合、トレーニング データはデジタル化された音楽トラック、歌詞、メタデータ、またはこれらの要素の組み合わせで構成されることがよくあります。 このデータの質、量、多様性はモデルの有効性に大きく影響します。

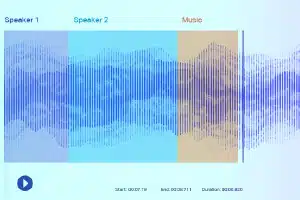
サウンドラベリング
サウンドのラベル付けでは、データ アノテーターに録音が与えられ、必要なすべてのサウンドを分離してラベルを付ける必要があります。 たとえば、特定のキーワードや特定の楽器の音などです。

音楽分類
データ アノテーターは、この種のオーディオ アノテーションでジャンルまたは楽器をマークできます。 音楽の分類は、音楽ライブラリを整理し、ユーザーのおすすめを改善するのに非常に役立ちます。

音声レベルのセグメンテーション
アカペラを歌っている個人の録音の波形とスペクトログラム上の音声セグメントのラベルと分類。
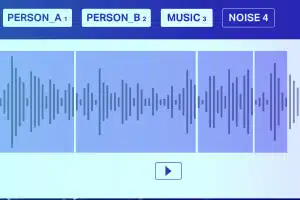
音の分類
無音/ホワイト ノイズを除いて、オーディオ ファイルは通常、音声、せせらぎ、音楽、およびノイズのサウンド タイプで構成されます。 音符に正確に注釈を付けて、精度を高めます。
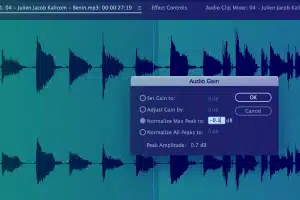
メタデータ情報の取得
開始時間、終了時間、セグメント ID、ラウドネス レベル、主サウンド タイプ、言語コード、スピーカー ID、その他の文字起こし規則などの重要な情報を取得します。


