過去XNUMX年以内に、あなたが出会ったすべての自動車メーカーは、自動運転車が市場に殺到する可能性に興奮していました。 いくつかの主要な自動車メーカーは、高速道路を自分で運転できる「かなり自律的ではない」車両を発売しましたが(もちろん、ドライバーからの絶え間ない監視の下で)、専門家が信じていたように、自律技術は実現していません。
2019年には、世界的に 1億1000万人 運用中の自動運転車(ある程度の自律性)。 この数は54年までに2024万に成長すると予測されています。傾向は、60年に3%減少したにもかかわらず、市場が2020%成長する可能性があることを示しています。
自動運転車が予想よりもはるかに遅れて発売される理由はたくさんありますが、主な理由のXNUMXつは、量、多様性、検証の点で質の高いトレーニングデータが不足していることです。 しかし、自動運転車の開発にトレーニングデータが重要なのはなぜですか?
自動運転車のトレーニングデータの重要性
自動運転車 AIの他のどのアプリケーションよりも、データ駆動型でデータ依存型です。 自動運転車システムの品質は、使用するトレーニングデータの種類、量、多様性に大きく依存します。
自動運転車が人間の介入を制限するか、まったく操作せずに運転できるようにするには、路上に存在するリアルタイムの刺激を理解し、認識し、対話する必要があります。 これが起こるために、いくつか ニューラルネットワーク 安全なナビゲーションを提供するために、センサーから収集されたデータを相互作用して処理する必要があります。
自動運転車のトレーニングデータを取得するにはどうすればよいですか?
信頼性の高いAVシステムは、車両がリアルタイムで遭遇する可能性のあるすべてのシナリオでトレーニングされます。 正確な車両の動作を生成するには、オブジェクトを認識し、環境変数を考慮に入れる準備をする必要があります。 しかし、すべてのエッジケースに正確に取り組むために、このような大量のデータセットを収集することは困難です。
AVシステムを適切にトレーニングするために、ビデオと画像の注釈技術を使用して、画像内のオブジェクトを識別および記述します。 トレーニングデータは、カメラで生成された写真を使用して収集され、画像を正確に分類してラベル付けすることで画像を識別します。
注釈付きの画像は、機械学習システムとコンピューターが必要なタスクを実行する方法を学習するのに役立ちます。 信号、道路標識、歩行者、気象条件、車両間の距離、深さ、およびその他の関連情報などのコンテキスト情報が提供されます。
いくつかの一流企業が異なる画像でトレーニングデータセットを提供し、 ビデオ注釈 開発者がAIモデルの開発に使用できる形式。
トレーニングデータはどこから取得されますか?
自動運転車は、さまざまなセンサーやデバイスを使用して、環境を取り巻く情報を収集、認識、解釈します。 人工知能を搭載した高性能AVシステムを開発するには、さまざまなデータと注釈が必要です。
使用されるツールのいくつかは次のとおりです。
カメラ:
車両に搭載されているカメラは、3Dおよび2Dの画像とビデオを記録します
レーダー:
レーダーは、物体の追跡、検出、および動きの予測に関する重要なデータを車両に提供します。 また、動的環境のデータが豊富な表現を構築するのにも役立ちます。

LiDaR(光検出および測距):
2D空間で3D画像を正確に解釈するには、LiDARを使用することが不可欠です。 LiDARは、レーザーを使用した深度と距離の測定および近接センシングに役立ちます。
自動運転車のトレーニングデータを収集する際の注意点
自動運転車のトレーニングは、XNUMX回限りの作業ではありません。 継続的な改善が必要です。 完全自動運転車は、人間の支援が必要な無人運転車よりも安全な代替手段になります。 しかし、このためには、システムは大量の多様な 高品質のトレーニングデータ。
ボリュームと多様性
あなたがあなたを訓練するとき、より良くそしてより信頼できるシステムを開発することができます 機械学習 大量の多様なデータセットのモデル。 データセットが十分であり、実際の経験が必要な場合を正確に特定できるデータ戦略が実施されています。
運転の特定の側面は、実際の経験からのみ得られます。 たとえば、自動運転車は、信号を出さずに方向転換したり、歩行者のジェイウォーキングに遭遇したりするなど、現実世界の逸脱したシナリオを予測する必要があります。
高品質ながら データ注釈 非常に役立ちますが、トレーニングと経験の過程で量と多様性の観点からデータを取得することもお勧めします。
注釈の高精度
機械学習モデルと深層学習モデルは、クリーンで正確なデータでトレーニングする必要があります。 自律型 自動車を運転する 信頼性が高まり、高レベルの精度が登録されていますが、それでも95%の精度から99%に移行する必要があります。 そのためには、道路をよりよく認識し、人間の行動の異常なルールを理解する必要があります。
高品質のデータ注釈手法を使用すると、機械学習モデルの精度を向上させることができます。
- 情報フローのギャップと格差を特定することから始め、データのラベル付け要件を最新の状態に保ちます。
- 実際のエッジケースシナリオに対処するための戦略を開発します。
- 最新のトレーニング目標を反映するために、モデルと品質のベンチマークを定期的に改善します。
- 常に最新のラベリングを使用する信頼できる経験豊富なデータトレーニングパートナーと提携し、 注釈手法 とベストプラクティス。
考えられるユースケース
物体の検出と追跡
画像内の歩行者、車、信号機などのオブジェクトに注釈を付けるために、いくつかの注釈手法が使用されます。 自動運転車が物事をより正確に検出および追跡するのに役立ちます。
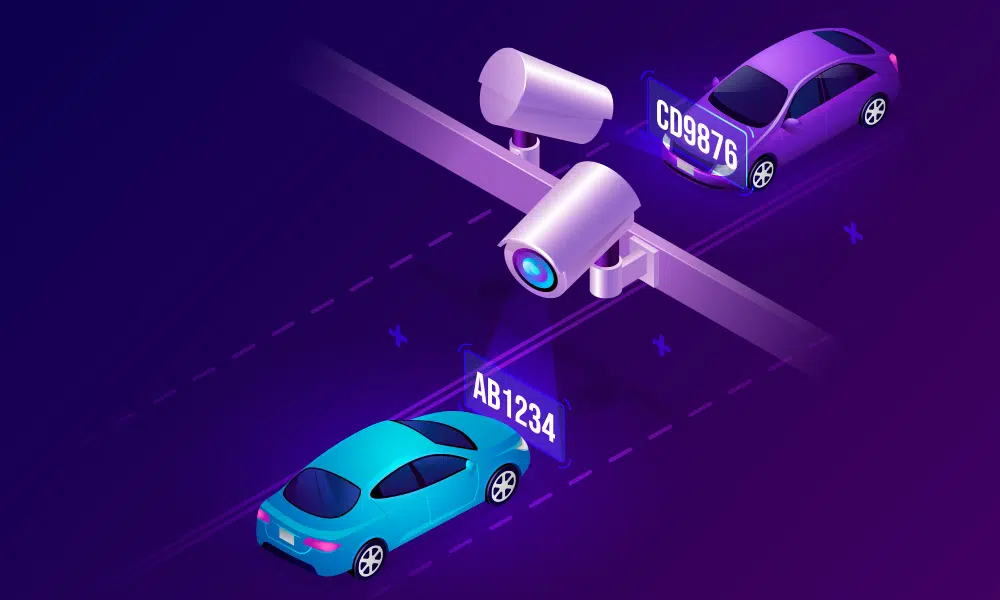
ナンバープレート検出
 バウンディングボックスの画像注釈技術を使用すると、ナンバープレートを簡単に見つけて車両の画像から抽出できます。
バウンディングボックスの画像注釈技術を使用すると、ナンバープレートを簡単に見つけて車両の画像から抽出できます。セマフォの分析
繰り返しになりますが、バウンディングボックス技術を使用すると、信号と看板を簡単に識別して注釈を付けることができます。
歩行者追跡システム
歩行者の追跡は、自動運転車が歩行者の動きを正確に特定できるように、すべてのビデオフレームで歩行者の動きを追跡して注釈を付けることによって行われます。
レーンの差別化
自動運転車システムの開発では、車線の差別化が重要な役割を果たします。 自動運転車では、ポリラインアノテーションを使用して車線、道路、歩道に線が引かれ、正確な車線の区別が可能になります。
ADASシステム
先進運転支援システムは、自動運転車が道路標識、歩行者、他の車、駐車支援、衝突警告を検出するのに役立ちます。 有効にするため コンピュータビジョン in ADAS、すべての道路標識の画像は、オブジェクトやシナリオを認識し、タイムリーなアクションを実行するために効果的に注釈を付ける必要があります。
ドライバーモニタリングシステム/キャビン内モニタリング
キャビン内の監視は、車両の乗員や他の人の安全を確保するのにも役立ちます。 キャビン内に配置されたカメラは、眠気、視線、注意散漫、感情などの重要なドライバー情報を収集します。 これらのキャビン内の画像は正確に注釈が付けられ、機械学習モデルのトレーニングに使用されます。
 バウンディングボックスの画像注釈技術を使用すると、ナンバープレートを簡単に見つけて車両の画像から抽出できます。
バウンディングボックスの画像注釈技術を使用すると、ナンバープレートを簡単に見つけて車両の画像から抽出できます。Shaipは、自動運転車システムに電力を供給するための高品質のトレーニングデータを企業に提供する上で重要な役割を果たしている、最高のデータ注釈会社です。 私たちの 画像のラベル付けと注釈の精度 ヘルスケア、小売、自動車などのさまざまな業界セグメントで主要なAI製品の構築を支援してきました。
すべての機械学習モデルと深層学習モデルに対応する多様なトレーニングデータセットを競争力のある価格で大量に提供しています。
信頼できる経験豊富なトレーニングデータプロバイダーを使用して、AIプロジェクトを変革する準備をしてください。