



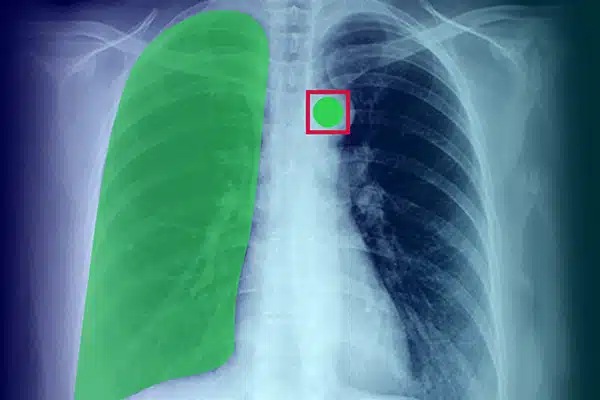
画像注釈
X 線、CT スキャン、MRI からの視覚データに注釈を付けることで医療 AI を強化します。専門家のデータラベル付けに基づいて、AI モデルが診断と治療で優れたパフォーマンスを発揮するようにします。優れた画像洞察により、患者の転帰を改善します。
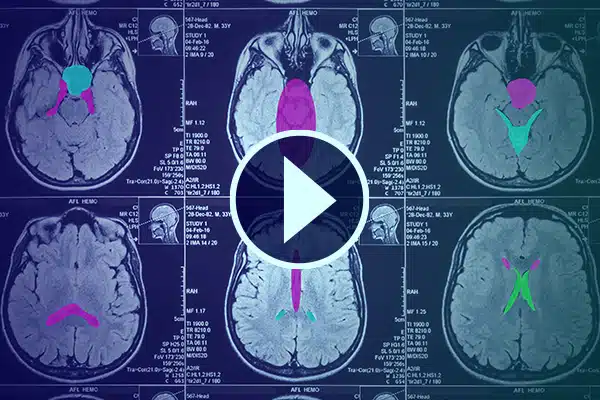
ビデオ注釈
詳細なビデオ注釈を使用してヘルスケアにおける AI を進歩させます。医療映像の分類とセグメンテーションにより AI 学習を強化します。外科用 AI と患者モニタリングを改善して、医療提供と診断を改善します。
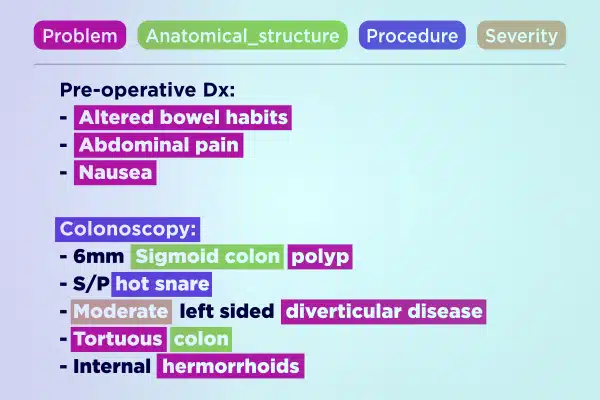
テキスト注釈
専門的に注釈が付けられたテキスト データを使用して医療 AI 開発を合理化します。手書きのメモから保険レポートに至るまで、膨大な量のテキストを迅速に解析して強化します。ヘルスケアの進歩に向けて、正確かつ実用的な洞察を確保します。

オーディオ注釈
NLP の専門知識を活用して、医療音声データに正確に注釈を付け、ラベルを付けます。シームレスな臨床業務を実現する音声支援システムを構築し、AI をさまざまな音声起動ヘルスケア製品に統合します。専門家の音声データキュレーションにより診断の精度を高めます。

医療コーディング
AI 医療コーディングを使用して医療文書を汎用コードに変換し、医療文書を合理化します。医療記録コーディングにおける最先端の AI 支援により、正確性を確保し、請求効率を向上させ、シームレスな医療サービスの提供をサポートします。

フェーズ1: 技術分野の専門知識 (範囲と注釈のガイドラインを理解する)

フェーズ2: プロジェクトに適したリソースのトレーニング

フェーズ3: 注釈付きドキュメントのフィードバックサイクルとQA
放射線学
当社の放射線画像アノテーション サービスは AI 診断を強化し、専門知識の層を追加します。各 X 線、MRI、CT スキャンは、対象分野の専門家によって注意深くラベル付けされ、レビューされます。トレーニングとレビューにおけるこの追加のステップにより、異常や病気を発見する AI の能力が向上します。顧客への納品前の精度が向上します。

心臓病学
心臓病学に焦点を当てた画像アノテーションにより、AI 診断が強化されます。当社は心臓病学の専門家を招いて、複雑な心臓関連の画像にラベルを付け、AI モデルをトレーニングします。データをクライアントに送信する前に、これらの専門家が各画像を確認して、最高の精度を確保します。このプロセスにより、AI は心臓の状態をより正確に検出できるようになります。
歯科
歯科における当社の画像アノテーション サービスは、歯科画像にラベルを付けて AI 診断ツールを強化します。当社の SME は、虫歯、歯並びの問題、その他の歯の状態を正確に特定することで、AI を活用して患者の転帰を改善し、歯科医による正確な治療計画と早期発見をサポートします。


















のワークプ
専任の訓練を受けたチーム:
- データ作成、ラベリング、QAのための30,000人以上の協力者
- 資格のあるプロジェクト管理チーム
- 経験豊富な製品開発チーム
- タレントプールソーシング&オンボーディングチーム

プロセス
最高のプロセス効率が保証されます:
- 堅牢な6シックスシグマステージゲートプロセス
- シックスシグマ黒帯の専任チーム–主要なプロセス所有者と品質コンプライアンス
- 継続的改善とフィードバックループ

プラットフォーム
特許取得済みのプラットフォームには次のような利点があります。
- Webベースのエンドツーエンドプラットフォーム
- 非の打ちどころのない品質
- より速いTAT
- シームレスな配信



