
OCRの利点
光学式文字認識–OCRテクノロジー –さまざまなメリットがあり、その一部は次のとおりです。
プロセスの速度を上げます。
非構造化データを機械で読み取り可能で検索可能な情報にすばやく変換することで、このテクノロジーはビジネスプロセスの速度を向上させるのに役立ちます。
精度を高める:
ヒューマンエラーのリスクが排除され、文字認識の全体的な精度が向上します。
処理コストを削減します。
光学式文字認識ソフトウェアは、他のテクノロジーに完全に依存しているわけではなく、処理コストを削減します。
生産性の向上:
情報はすぐに利用可能で検索可能であるため、従業員は生産的なタスクを実行して目標を達成するためにより多くの時間を費やすことができます。
顧客満足度の向上:
簡単に検索できる形式で情報を利用できるため、満足度が高くなり、顧客体験が向上します。
ユースケースとアプリケーション
文書の保存/文書のデジタル化
 価値のある古い歴史的文書は、デジタル化された形式に変換することにより、保存、保存、および破壊不能にすることができます。 OCR技術は、骨董品や珍しい本のデジタル化に使用されているため、不規則なフォントのこれらの原稿は、デジタルで変更して将来検索できるようにすることができます。
価値のある古い歴史的文書は、デジタル化された形式に変換することにより、保存、保存、および破壊不能にすることができます。 OCR技術は、骨董品や珍しい本のデジタル化に使用されているため、不規則なフォントのこれらの原稿は、デジタルで変更して将来検索できるようにすることができます。
銀行と金融
銀行および金融セクターは、OCTテクノロジーを最大限に活用しています。 このテクノロジーは、セキュリティ詐欺の防止を改善し、リスクを軽減し、処理を高速化するのに役立ちます。 銀行と銀行アプリは、OCRを使用して、口座番号、金額、手の署名などのチェックから重要なデータを抽出します。 OCRは、ローンや住宅ローンの申し込み、請求書、給与明細の処理を高速化するのに役立ちます。
OCRが一般的になる前は、記録、領収書、明細書、小切手などのすべての銀行文書は物理的なものでした。 OCRのデジタル化により、銀行や金融機関は、データにすばやくアクセスすることで、プロセスを合理化し、手動エラーを排除し、プロセスの効率を向上させることができます。
ナンバープレート認識
 OCRテクノロジーは、ナンバープレートの数字とテキストを識別するために広く使用されています。 この技術は、紛失した車の特定、駐車料金の計算、および車両犯罪の防止に使用されています。
OCRテクノロジーは、ナンバープレートの数字とテキストを識別するために広く使用されています。 この技術は、紛失した車の特定、駐車料金の計算、および車両犯罪の防止に使用されています。
OCRテクノロジーは、詐欺や犯罪を回避するための交通安全ルールの実装を支援しています。 車両のナンバープレートはドライバーの資格情報にリンクされているため、識別が容易です。
さらに、ナンバープレートは、AIモデルが読みやすく、より正確になるように、よく書かれた数字とテキストの束で構成されています。
テキスト読み上げ
OCRテクノロジーのテキスト読み上げアプリケーションは、視覚障害のある人がより簡単に機能するための優れたヘルプです。 OCRテクノロジーは、物理テキストとデジタルテキストのスキャン、および音声デバイスの使用に役立ちます。 その後、コンテンツが読み上げられます。 OCRテクノロジーのテキスト読み上げの側面は最初のアプリケーションのXNUMXつでしたが、現在では、いくつかの方言と言語をサポートすることにより、視覚障害者の固有のニーズに応えるために進化し、進歩しています。
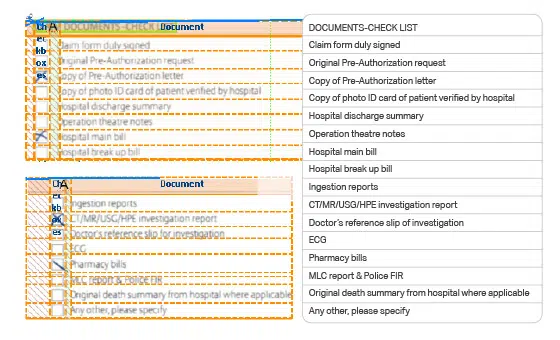
マルチカテゴリの転写 スキャンされた紙のドキュメント データセット
 OCRテクノロジーを使用して、請求書、領収書、請求書、およびさまざまなカテゴリの他のドキュメントも効果的に転記されます。 ニュースレター、丸で囲んだ数字の紙、チェックボックスフォーム、税務フォームやマニュアルなどのいくつかのカテゴリのドキュメントもデジタル化できます。
OCRテクノロジーを使用して、請求書、領収書、請求書、およびさまざまなカテゴリの他のドキュメントも効果的に転記されます。 ニュースレター、丸で囲んだ数字の紙、チェックボックスフォーム、税務フォームやマニュアルなどのいくつかのカテゴリのドキュメントもデジタル化できます。
OCRで医療ラベルを転写する
 OCRを使用して処方医療ラベルのスキャンを支援することにより、医療データを自動的にキャプチャできるようになりました。 医療 データがキャプチャされます 手書きの処方箋、薬の情報、および量から、手動のエラー、重複、および過失を回避します。
OCRを使用して処方医療ラベルのスキャンを支援することにより、医療データを自動的にキャプチャできるようになりました。 医療 データがキャプチャされます 手書きの処方箋、薬の情報、および量から、手動のエラー、重複、および過失を回避します。
OCRを使用すると、医療業界は患者の病歴をすばやくスキャン、保存、検索できます。 OCRを使用すると、スキャンレポート、治療履歴、病院の記録、保険の記録、X線、およびその他のドキュメントをデジタル化して保存できます。 OCRは、医療ラベルをデジタル化、転写、および保存することにより、プロセスフローを合理化し、医療をスピードアップすることを容易にします。
OCRを使用したストリート/道路および情報の抽出ストリートボードデータの検出
 道路/道路標識の自動検出、識別、分類はOCRで行われています。 OCRは道路標識を検出することで、ドライバーをより安全な旅に導きます。 OCRテクノロジーは、暗い場所でも同様に機能し、複数の言語の道路標識やさまざまな形状の看板を検出し、将来のために同じものを分類します。
道路/道路標識の自動検出、識別、分類はOCRで行われています。 OCRは道路標識を検出することで、ドライバーをより安全な旅に導きます。 OCRテクノロジーは、暗い場所でも同様に機能し、複数の言語の道路標識やさまざまな形状の看板を検出し、将来のために同じものを分類します。
開発するには インテリジェント文字認識 ツールの場合、プロジェクト固有のデータセットを使用してトレーニングする必要があります。
Shaipでは、完全にカスタマイズされたドキュメントデータセットを提供して、高機能を開発します AIおよびMLモデルのOCR。 私たちの専門 OCRのプロセス クライアント向けに最適化されたソリューションの開発に役立ちます。
スキャンされたドキュメントから抽出された何千もの多様なデータを含む、広範囲で信頼性の高いデータセットを提供します。 私たちと連絡を取る OCRソリューション スケーラブルで手頃な価格のクライアント固有のデータセットを提供する方法を知る専門家。


