






テキストコレクション

オーディオ/スピーチコレクション
テキスト注釈
音声/音声注釈

テキストの文字起こし

音声/音声文字変換




会話型AI /チャットボットトレーニング
デジタルアシスタントのトレーニングには、さまざまな地域、言語、方言、設定、形式からの高品質のデータが大量に必要です。 Shaipでは、必要な知識とドメインの専門知識を持ち、クライアントの特定のニーズを十分に認識しているヒューマンインザループのAIモデルのトレーニングデータを提供しています。
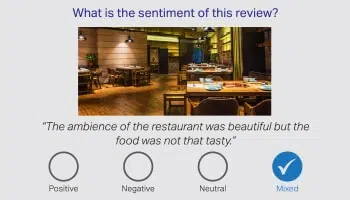
感情/意図
分析
言葉だけでは全体像を伝えることができず、人間の言語の曖昧さを解釈する責任は人間のアノテーターにあると正しく言われています。 したがって、会話に基づいて顧客の感情を特定することが最も重要です。 さまざまな分野の言語専門家が、製品レビュー、金融ニュース、ソーシャルメディアのニュアンスを解釈できます。

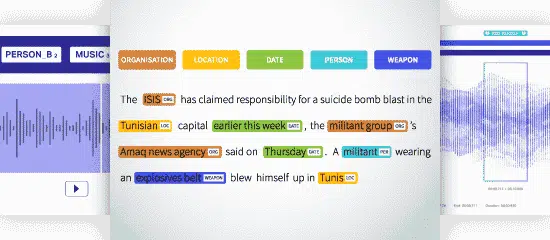
固有表現抽出(NER)
固有表現抽出(NER)は、テキスト内の固有表現抽出を識別、抽出、および分類して、事前定義されたカテゴリに分類します。 テキストは、場所、名前、組織、製品、数量、価値、パーセンテージなどに分類できます。NERを使用すると、記事で言及された組織など、実際の質問に答えることができます。
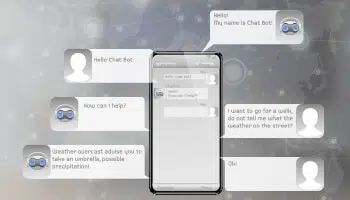
クライアントサービスの自動化
堅牢で十分に訓練された仮想チャットボットまたはデジタルアシスタントは、顧客が売り手と通信する方法に革命をもたらし、顧客体験を大幅に向上させました。

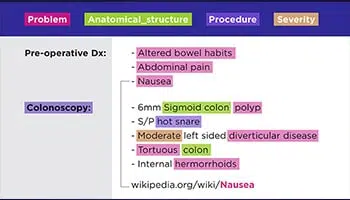
テキストの文字起こし
医師の手書きの処方箋から会議のメモまで、当社のスペシャリストは、アーカイブされたドキュメント、法的契約、患者の健康記録など、あらゆる形式のデータをデジタル化できます。
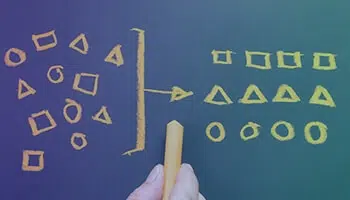
コンテンツの分類
分類またはタグ付けとも呼ばれる分類は、テキストを整理されたグループに分類し、関心のある機能に基づいてラベルを付けるプロセスです。

トピック分析
トピック分析またはトピックのラベル付けとは、検討中の繰り返しのトピック/テーマを特定することにより、特定のテキストから意味を特定して抽出することです。

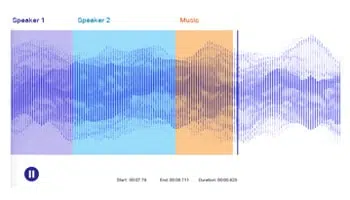
音声文字変換
スピーチ/ポッドキャスト/セミナーを書き起こし、会話をテキストに呼び出します。 人間を活用してオーディオ/音声ファイルに正確に注釈を付け、NLPモデルを正確にトレーニングします。

オーディオ分類
音または発話を分類して、言語、方言、セマンティクス、辞書などに基づいて音声/音声を分類します。

のワークプ
専任の訓練を受けたチーム:
- データ作成、ラベリング、QAのための30,000人以上の協力者
- 資格のあるプロジェクト管理チーム
- 経験豊富な製品開発チーム
- タレントプールソーシング&オンボーディングチーム

プロセス
最高のプロセス効率が保証されます:
- 堅牢な6シックスシグマステージゲートプロセス
- シックスシグマ黒帯の専任チーム–主要なプロセス所有者と品質コンプライアンス
- 継続的改善とフィードバックループ

プラットフォーム
特許取得済みのプラットフォームには次のような利点があります。
- Webベースのエンドツーエンドプラットフォーム
- 非の打ちどころのない品質
- より速いTAT
- シームレスな配信


