
AI、ビッグデータ、機械学習は、世界中の政策立案者、企業、科学、メディアハウス、およびさまざまな業界に影響を与え続けています。 レポートによると、AI の世界的な採用率は現在、 35中2022% – 4 年からなんと 2021% の増加です。さらに 42% の企業が、自社のビジネスに対する AI の多くの利点を模索していると報告されています。
多くの AI イニシアチブを強化し、 機械学習 ソリューションはデータです。 AI は、アルゴリズムに供給されるデータと同程度にしか機能しません。 低品質のデータは、低品質の結果と不正確な予測につながる可能性があります。
ML および AI ソリューションの開発に多くの注目が集まっていますが、質の高いデータセットとは何かという認識が欠けています。 この記事では、タイムラインをナビゲートします 質の高いAIトレーニングデータ データ収集とトレーニングの理解を通じて、AI の未来を特定します。
AI トレーニング データの定義
ML ソリューションを構築する場合、トレーニング データセットの量と質が重要です。 ML システムは、大量の動的で偏りのない貴重なトレーニング データを必要とするだけでなく、大量のトレーニング データも必要とします。
しかし、AI トレーニング データとは何ですか?
AI トレーニング データは、正確な予測を行うために ML アルゴリズムをトレーニングするために使用されるラベル付きデータのコレクションです。 ML システムは、パターンを認識して識別し、パラメーター間の関係を理解し、必要な決定を下し、トレーニング データに基づいて評価しようとします。
たとえば、自動運転車の例を見てみましょう。 自動運転 ML モデルのトレーニング データセットには、車、歩行者、道路標識、その他の車両のラベル付き画像と動画を含める必要があります。
つまり、ML アルゴリズムの品質を向上させるには、適切に構造化され、注釈が付けられ、ラベル付けされた大量のトレーニング データが必要です。
高品質のトレーニング データの重要性とその進化
高品質のトレーニング データは、AI および ML アプリの開発における重要なインプットです。 データはさまざまなソースから収集され、機械学習の目的には適さない整理されていない形式で表示されます。 ラベル付け、注釈付け、タグ付けされた高品質のトレーニング データは常に整理された形式であり、ML トレーニングに最適です。
高品質のトレーニング データを使用すると、ML システムがオブジェクトを認識し、事前に定義された特徴に従ってそれらを分類しやすくなります。 分類が正確でない場合、データセットは悪いモデル結果をもたらす可能性があります。
AI トレーニング データの黎明期
AI が現在のビジネスと研究の世界を支配しているにもかかわらず、ML が支配する前の初期の時代 Artificial Intelligence かなり違いました。
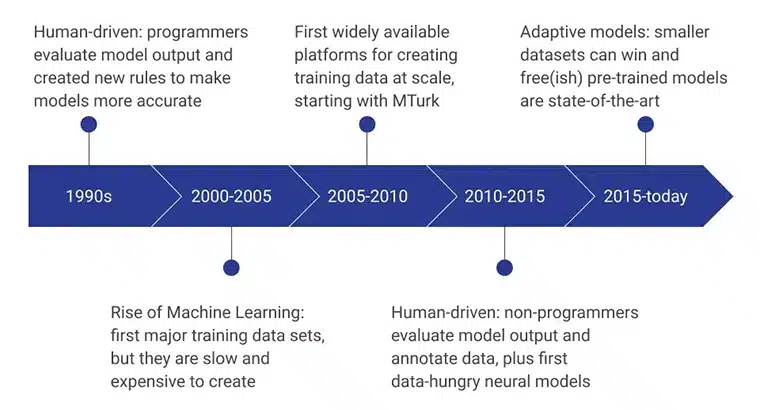
AI トレーニング データの初期段階は、モデルをより効率的にする新しいルールを一貫して考案することにより、モデルの出力を評価する人間のプログラマーによって強化されました。 2000 年から 2005 年にかけて、最初の主要なデータセットが作成されましたが、これは非常に遅く、リソースに依存し、費用のかかるプロセスでした。 これにより、トレーニング データセットが大規模に開発されるようになり、Amazon の MTurk は、データ収集に対する人々の認識を変える上で重要な役割を果たしました。 同時に、人間によるラベル付けと注釈も始まりました。
次の数年間は、非プログラマーによるデータ モデルの作成と評価に焦点が当てられました。 現在、高度なトレーニング データ収集方法を使用して開発された事前トレーニング済みモデルに焦点が当てられています。
質より量
当時、AI トレーニング データセットの整合性を評価する際、データ サイエンティストは以下に焦点を当てていました。 AI トレーニング データ量 オーバークオリティ。
たとえば、大規模なデータベースが正確な結果を提供するという一般的な誤解がありました。 データの膨大な量は、データの価値を示す良い指標であると考えられていました。 量は、データセットの価値を決定する主要な要因の XNUMX つにすぎません。データ品質の役割が認識されました。
という認識は データ品質 データの完全性、信頼性、有効性、可用性、および適時性に依存します。 最も重要なことは、プロジェクトに対するデータの適合性が、収集されたデータの品質を決定したことです。
不十分なトレーニング データによる初期の AI システムの制限
不十分なトレーニング データは、高度なコンピューティング システムの欠如と相まって、初期の AI システムのいくつかの約束が果たされなかった理由の XNUMX つです。
質の高いトレーニング データが不足しているため、ML ソリューションは視覚パターンを正確に特定できず、ニューラル研究の発展を妨げていました。 多くの研究者が音声言語認識の可能性を認識していましたが、音声データセットが不足しているため、音声認識ツールの研究や開発は実現できませんでした。 ハイエンドの AI ツールを開発する際のもう XNUMX つの大きな障害は、コンピューターの計算能力とストレージ能力の欠如でした。
高品質のトレーニング データへの移行
データセットの品質が重要であるという認識に顕著な変化がありました。 ML システムが人間の知性と意思決定能力を正確に模倣するためには、大量の高品質のトレーニング データで成功する必要があります。
ML データをアンケートと考えてください。 データサンプル サイズ、より良い予測。 サンプル データにすべての変数が含まれていない場合、パターンが認識されなかったり、不正確な結論が得られたりする可能性があります。
AI 技術の進歩とより良いトレーニング データの必要性
 AI テクノロジーの進歩により、高品質のトレーニング データの必要性が高まっています。
AI テクノロジーの進歩により、高品質のトレーニング データの必要性が高まっています。より良いトレーニング データが信頼できる ML モデルの可能性を高めるという理解は、より良いデータ収集、注釈、およびラベル付けの方法論を生み出しました。 データの品質と関連性は、AI モデルの品質に直接影響を与えました。
 AI テクノロジーの進歩により、高品質のトレーニング データの必要性が高まっています。
AI テクノロジーの進歩により、高品質のトレーニング データの必要性が高まっています。データの品質と精度への関心の高まり
ML モデルが正確な結果を提供し始めるために、反復的なデータ調整ステップを経る高品質のデータセットが提供されます。
たとえば、人間は特定の犬種を写真、ビデオ、または直接紹介されてから数日以内に認識できる場合があります。 人間は自分の経験と関連する情報から引き出して、必要に応じてこの知識を記憶し、引き出します。 しかし、機械にとってはそう簡単には機能しません。 マシンは、その特定の品種と他の品種の明確な注釈とラベル付きの画像 (数百または数千) を入力して、接続を確立する必要があります。
AI モデルは、トレーニングされた情報と、 現実の世界. トレーニング データに関連情報が含まれていない場合、アルゴリズムは役に立たなくなります。
多様で代表的なトレーニングデータの重要性
データの多様性が高まると、能力が向上し、偏見が減り、すべてのシナリオを公平に表現できるようになります。 AI モデルが同種のデータセットを使用してトレーニングされている場合、新しいアプリケーションが特定の目的でのみ機能し、特定の母集団にサービスを提供することを確信できます。データセットは、特定の人口、人種、性別、選択、知的意見に偏り、モデルが不正確になる可能性があります。
被験者プールの選択、キュレーション、注釈、ラベル付けを含むデータ収集プロセス全体の流れが、適切に多様で、バランスが取れており、母集団を代表していることを確認することが重要です。
 データの多様性が高まると、能力が向上し、偏見が減り、すべてのシナリオを公平に表現できるようになります。 AI モデルが同種のデータセットを使用してトレーニングされている場合、新しいアプリケーションが特定の目的でのみ機能し、特定の母集団にサービスを提供することを確信できます。
データの多様性が高まると、能力が向上し、偏見が減り、すべてのシナリオを公平に表現できるようになります。 AI モデルが同種のデータセットを使用してトレーニングされている場合、新しいアプリケーションが特定の目的でのみ機能し、特定の母集団にサービスを提供することを確信できます。AI トレーニング データの未来
AI モデルの将来の成功は、ML アルゴリズムのトレーニングに使用されるトレーニング データの質と量にかかっています。 このデータの質と量の関係はタスク固有のものであり、明確な答えがないことを認識することが重要です。
最終的に、トレーニング データ セットの妥当性は、構築された目的に対して確実に適切に機能する能力によって定義されます。
データ収集と注釈技術の進歩
ML はフィードされたデータに敏感であるため、データ収集と注釈ポリシーを合理化することが不可欠です。 データ収集、キュレーション、虚偽表示、不完全な測定、不正確なコンテンツ、データの重複、および誤った測定におけるエラーは、不十分なデータ品質の一因となります。
データ マイニング、Web スクレイピング、およびデータ抽出による自動データ収集は、より高速なデータ生成への道を開いています。 さらに、事前にパッケージ化されたデータセットは、迅速なデータ収集手法として機能します。
クラウドソーシングは、データ収集のもう XNUMX つの画期的な方法です。 データの正確性は保証できませんが、公共のイメージを収集するための優れたツールです。 最後に、特化 データ収集 専門家は、特定の目的のためにソース化されたデータも提供します。
トレーニング データにおける倫理的配慮の重要性が高まる
AI の急速な進歩に伴い、特にトレーニング データの収集において、いくつかの倫理的問題が発生しています。 トレーニング データ収集における倫理的な考慮事項には、インフォームド コンセント、透明性、バイアス、データ プライバシーなどがあります。現在、データには顔画像、指紋、音声録音、その他の重要な生体認証データが含まれているため、費用のかかる訴訟や評判への損害を回避するために、法的および倫理的な慣行を確実に遵守することが非常に重要になっています。
将来的にはさらに質の高い多様なトレーニング データの可能性
~には大きな可能性がある 高品質で多様なトレーニング データ 将来。 データ品質に対する認識と、AI ソリューションの品質要求に応えるデータ プロバイダーの可用性のおかげです。
現在のデータ プロバイダーは、画期的なテクノロジを使用して、倫理的かつ合法的に膨大な量の多様なデータセットを調達することに長けています。 また、さまざまな ML プロジェクト用にカスタマイズされたデータにラベルを付け、注釈を付け、提示するための社内チームもあります。
 AI の急速な進歩に伴い、特にトレーニング データの収集において、いくつかの倫理的問題が発生しています。 トレーニング データ収集における倫理的な考慮事項には、インフォームド コンセント、透明性、バイアス、データ プライバシーなどがあります。
AI の急速な進歩に伴い、特にトレーニング データの収集において、いくつかの倫理的問題が発生しています。 トレーニング データ収集における倫理的な考慮事項には、インフォームド コンセント、透明性、バイアス、データ プライバシーなどがあります。まとめ
データと品質をよく理解している信頼できるベンダーと提携することが重要です。 ハイエンド AI モデルの開発. Shaip は、AI プロジェクトのニーズと目標を満たすカスタマイズされたデータ ソリューションを提供することに長けた最高の注釈会社です。 私たちと提携して、私たちが提供する能力、コミットメント、コラボレーションを探求してください。


