
堅牢なAIベースのソリューションは、データだけでなく、高品質で正確に注釈が付けられたデータに基づいて構築されています。 AIプロジェクトを強化できるのは、最高で最も洗練されたデータだけです。このデータの純度は、プロジェクトの結果に大きな影響を与えます。
私たちはしばしばデータをAIプロジェクトの燃料と呼んでいますが、データだけで十分というわけではありません。 プロジェクトのリフトオフを達成するためにロケット燃料が必要な場合、原油をタンクに入れることはできません。 代わりに、最高品質の情報のみがプロジェクトに力を与えるように、データ(燃料など)を注意深く改良する必要があります。 その改良プロセスはデータ注釈と呼ばれ、それについてはかなりの数の永続的な誤解があります。
アノテーションでトレーニングデータの品質を定義する
データ品質がAIプロジェクトの結果に大きな違いをもたらすことを私たちは知っています。 最高で最も高性能なMLモデルのいくつかは、詳細で正確にラベル付けされたデータセットに基づいています。
しかし、注釈の品質をどのように正確に定義するのでしょうか。
私たちが話すとき データ注釈 品質、精度、信頼性、および一貫性が重要です。 データセットは、グラウンドトゥルースおよび実世界の情報と一致する場合に正確であると言われます。
データの一貫性とは、データセット全体で維持される精度のレベルを指します。 ただし、データセットの品質は、プロジェクトのタイプ、その固有の要件、および望ましい結果によってより正確に決定されます。 したがって、これはデータのラベル付けと注釈の品質を決定するための基準となるはずです。
データ品質を定義することが重要なのはなぜですか?
データ品質は、プロジェクトの品質と結果を決定する包括的な要素として機能するため、定義することが重要です。
- 質の悪いデータは、製品およびビジネス戦略に影響を与える可能性があります。
- 機械学習システムは、トレーニング対象のデータの品質と同じくらい優れています。
- 質の高いデータは、それに関連するやり直しやコストを排除します。
- これは、企業が情報に基づいたプロジェクトの決定を下し、規制コンプライアンスを順守するのに役立ちます。
ラベル付け中にトレーニングデータの品質を測定するにはどうすればよいですか?

トレーニングデータの品質を測定する方法はいくつかありますが、そのほとんどは、最初に具体的なデータ注釈ガイドラインを作成することから始まります。 いくつかの方法が含まれます:
専門家によって確立されたベンチマーク
品質ベンチマークまたは ゴールドスタンダードアノテーション メソッドは、プロジェクトの出力品質を測定する基準点として機能する、最も簡単で手頃な品質保証オプションです。 専門家によって確立されたベンチマークに対してデータ注釈を測定します。
クロンバックのアルファテスト
クロンバックのアルファテストは、データセットアイテム間の相関または一貫性を決定します。 ラベルの信頼性と より高い精度 研究に基づいて測定することができます。
コンセンサス測定
コンセンサス測定は、機械または人間のアノテーター間の一致のレベルを決定します。 通常、各項目についてコンセンサスが得られ、意見の相違がある場合は調停する必要があります。
パネルレビュー
専門家パネルは通常、データラベルを確認することによってラベルの正確さを判断します。 場合によっては、データラベルの定義された部分が、通常、精度を判断するためのサンプルとして取得されます。
検討する トレーニングデータ 品質
AIプロジェクトに取り組んでいる企業は、自動化の力に完全に夢中になっています。そのため、AIによって駆動される自動注釈は、手動で注釈を付けるよりも高速で正確であると多くの人が考え続けています。 今のところ、精度が非常に重要であるため、データを識別して分類するには人間が必要であるというのが現実です。 自動ラベル付けによって作成された追加のエラーは、アルゴリズムの精度を向上させるために追加の反復を必要とし、時間の節約を無効にします。
もうXNUMXつの誤解(および自動注釈の採用に貢献している可能性が高いもの)は、小さなエラーは結果にあまり影響を与えないというものです。 入力データの不整合がプログラマーが意図していなかった方向にアルゴリズムを導くAIドリフトと呼ばれる現象のために、最小のエラーでさえ重大な不正確さを生み出す可能性があります。
トレーニングデータの品質(正確性と一貫性の側面)は、プロジェクトの固有の要求を満たすために一貫してレビューされます。 トレーニングデータのレビューは、通常、XNUMXつの異なる方法を使用して実行されます–
自動注釈付きテクニック
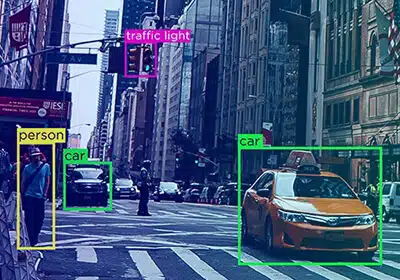 自動注釈レビュープロセスは、フィードバックがシステムにループバックされることを保証し、誤謬を防ぎ、アノテーターがプロセスを改善できるようにします。
自動注釈レビュープロセスは、フィードバックがシステムにループバックされることを保証し、誤謬を防ぎ、アノテーターがプロセスを改善できるようにします。
人工知能によって駆動される自動注釈は正確で高速です。 自動アノテーションにより、手動のQAがレビューに費やす時間が短縮され、データセット内の複雑で重大なエラーにより多くの時間を費やすことができます。 自動注釈は、無効な回答、繰り返し、誤った注釈の検出にも役立ちます。
データサイエンスの専門家を介して手動で
データサイエンティストは、データセットの正確性と信頼性を確保するためにデータ注釈も確認します。
小さなエラーや注釈の不正確さは、プロジェクトの結果に大きな影響を与える可能性があります。 また、これらのエラーは、自動注釈レビューツールでは検出されない場合があります。 データサイエンティストは、さまざまなバッチサイズからサンプル品質テストを実行して、データセット内のデータの不整合や意図しないエラーを検出します。
すべてのAI見出しの背後には注釈プロセスがあり、Shaipはそれを無痛にするのに役立ちます
AIプロジェクトの落とし穴の回避
多くの組織は、社内の注釈リソースの不足に悩まされています。 データサイエンティストとエンジニアの需要は高く、AIプロジェクトに取り組むのに十分な数のこれらの専門家を雇うことは、ほとんどの企業にとって手の届かない小切手を書くことを意味します。 最終的にあなたを悩ませることになる予算オプション(クラウドソーシングアノテーションなど)を選択する代わりに、経験豊富な外部パートナーにアノテーションのニーズをアウトソーシングすることを検討してください。 アウトソーシングは、社内チームを編成しようとするときに発生する採用、トレーニング、および管理のボトルネックを減らしながら、高度な精度を保証します。
特にShaipを使用して注釈のニーズを外部委託する場合、すべての重要な結果を損なうショートカットなしでAIイニシアチブを加速できる強力な力を利用します。 私たちは完全に管理された労働力を提供します。つまり、クラウドソーシングによる注釈の取り組みよりもはるかに高い精度を得ることができます。 先行投資は多額になる可能性がありますが、目的の結果を達成するために必要な反復回数が少ない開発プロセス中に見返りがあります。
当社のデータサービスは、他のほとんどのラベリングプロバイダーが提供できない機能であるソーシングを含むプロセス全体もカバーしています。 私たちの経験により、匿名化され、関連するすべての規制に準拠している、地理的に多様な高品質の大量のデータをすばやく簡単に取得できます。 このデータをクラウドベースのプラットフォームに格納すると、プロジェクトの全体的な効率を高め、思ったよりも早く進行するのに役立つ、実績のあるツールとワークフローにアクセスすることもできます。
そして最後に、 社内の業界専門家 あなたのユニークなニーズを理解してください。 チャットボットを構築している場合でも、顔認識テクノロジーを適用してヘルスケアを改善する場合でも、アノテーションプロセスがプロジェクトで概説されている目標を確実に達成するためのガイドラインの作成を支援します。
Shaipでは、AIの新時代に興奮しているだけではありません。 私たちは信じられないほどの方法でそれを支援しており、私たちの経験は私たちが無数の成功したプロジェクトを軌道に乗せるのに役立ちました。 あなた自身の実装のために私たちが何ができるかを知るために、私たちに連絡してください デモをリクエストする 。


