
人工知能とビッグデータは、グローバルな問題の解決策を見つけながら、地域の問題を優先し、多くの深遠な方法で世界を変革する可能性を秘めています。 AI は、家庭から職場まで、あらゆる場面でソリューションをもたらします。 AIコンピューター、 機械学習 自動化されたパーソナライズされた方法でインテリジェントな行動と会話をシミュレートできます。
しかし、AI は包摂の問題に直面しており、偏見を持っていることがよくあります。 幸いなことに、焦点を当てる 人工知能の倫理 多様なトレーニングデータを通じて無意識の偏見を排除することで、多様化と包摂の観点から新しい可能性を導き出すことができます。
AI トレーニング データの多様性の重要性
 一方が他方に影響を与え、AI ソリューションの結果に影響を与えるため、トレーニング データの多様性と品質は関連しています。 AI ソリューションの成功は、 多様なデータ それは訓練されています。 データの多様性により、AI のオーバーフィッティングが防止されます。つまり、モデルは、トレーニングに使用されたデータのみを実行または学習します。 オーバーフィッティングでは、AI モデルは、トレーニングで使用されていないデータでテストされたときに結果を提供できません。
一方が他方に影響を与え、AI ソリューションの結果に影響を与えるため、トレーニング データの多様性と品質は関連しています。 AI ソリューションの成功は、 多様なデータ それは訓練されています。 データの多様性により、AI のオーバーフィッティングが防止されます。つまり、モデルは、トレーニングに使用されたデータのみを実行または学習します。 オーバーフィッティングでは、AI モデルは、トレーニングで使用されていないデータでテストされたときに結果を提供できません。
AIトレーニングの現状 データ
データの不平等や多様性の欠如は、不公平で非倫理的で非包括的な AI ソリューションにつながり、差別を深める可能性があります。 しかし、データの多様性が AI ソリューションにどのように、そしてなぜ関係するのでしょうか?
すべてのクラスの不平等な表現は、顔の誤認につながります。重要な例の XNUMX つは、黒人のカップルを「ゴリラ」として分類した Google フォトです。 そしてMetaは、黒人男性の動画を見ているユーザーに対して、「霊長類の動画を続けて視聴する」かどうかを尋ねます。
たとえば、特にチャットボットにおける民族的または人種的マイノリティの不正確または不適切な分類は、AI トレーニング システムに偏見をもたらす可能性があります。 2019年のレポートによると 識別システム – 性別、人種、AI の力、AI の教師の 80% 以上が男性です。 FB の女性 AI 研究者は、Google では 15%、Google では 10% しか占めていません。
AI パフォーマンスに対する多様なトレーニング データの影響
 特定のグループやコミュニティをデータ表現から除外すると、歪んだアルゴリズムになる可能性があります。
特定のグループやコミュニティをデータ表現から除外すると、歪んだアルゴリズムになる可能性があります。
データ バイアスは、特定の人種やグループをアンダーサンプリングすることによって、データ システムに誤って導入されることがよくあります。 顔認識システムがさまざまな顔でトレーニングされると、モデルが顔の器官の位置や色のバリエーションなどの特定の特徴を識別するのに役立ちます。
ラベルの頻度が不均衡であることのもう XNUMX つの結果は、短時間で出力を生成するために加圧されたときに、システムが少数派を異常と見なす可能性があることです。
AI トレーニング データの多様性の実現
一方で、多様なデータセットを生成することも課題です。 特定のクラスに関するデータが完全に不足しているため、表現が不十分になる可能性があります。 スキル、民族性、人種、性別、規律などに関して、AI 開発者チームをより多様化することで軽減できます。 さらに、AI におけるデータの多様性の問題に対処する理想的な方法は、データの収集とキュレーションの段階で多様性を注入することです。
AI の誇大宣伝に関係なく、AI は依然として人間によって収集、選択、およびトレーニングされたデータに依存しています。 人間の生来の偏見は、彼らが収集したデータに反映され、この無意識の偏見は ML モデルにも忍び込みます。
多様なトレーニング データの収集とキュレーションの手順
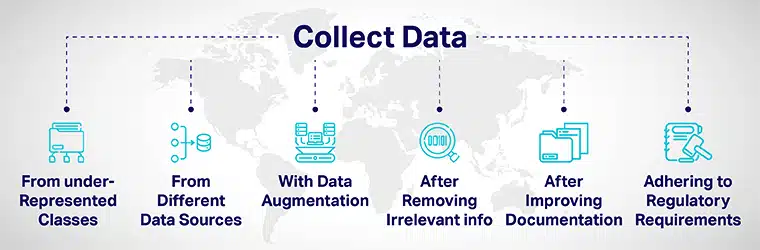
データの多様性 次の方法で達成できます。
- 十分に表現されていないクラスから慎重にデータを追加し、モデルをさまざまなデータ ポイントに公開します。
- さまざまなデータ ソースからデータを収集する。
- 元のデータ ポイントとは明らかに異なる新しいデータ ポイントを増やす/含めるために、データの増強または人為的にデータセットを操作することによって。
- AI 開発プロセスの応募者を採用するときは、応募書類から仕事に関係のない情報をすべて削除してください。
- モデルの開発と評価の文書化を改善することにより、透明性と説明責任を改善します。
- 多様性を構築するための規制を導入し、 AI の包括性 草の根レベルからのシステム。 さまざまな政府が、多様性を確保し、不公平な結果をもたらす可能性のある AI バイアスを軽減するためのガイドラインを作成しています。
[ また読む: AI トレーニング データ収集プロセスの詳細 ]
まとめ
現在、AI ソリューションの開発に専念している大手テクノロジー企業やラーニング センターはごくわずかです。 これらのエリート空間には、排除、差別、偏見が染み込んでいます。 しかし、これらは AI が開発されている空間であり、これらの高度な AI システムの背後にあるロジックは、過小評価されているグループが負うのと同じ偏見、差別、排除に満ちています。
多様性と差別の禁止について議論する際には、それが利益をもたらす人々と害を及ぼす人々に疑問を投げかけることが重要です。 AI が不利な立場に置かれている人についても検討する必要があります。「普通の」人間という考えを強制することで、AI は潜在的に「他の人」を危険にさらす可能性があります。
力関係、公平性、正義を認めずに AI データの多様性について議論しても、全体像は見えません。 AI トレーニング データの多様性の範囲と、人間と AI が協力してこの危機を緩和する方法を完全に理解するために、 Shaip のエンジニアに連絡する. AI ソリューションに動的で多様なデータを提供できる多様な AI エンジニアがいます。


