
自動音声認識 (ASR) は長い道のりを歩んできました。 ずっと前に発明されましたが、ほとんど誰も使用していませんでした。 しかし、時代と技術は現在大きく変化しています。 オーディオの文字起こしは大幅に進化しています。
AI (人工知能) などのテクノロジーにより、音声からテキストへの翻訳プロセスが強化され、迅速かつ正確な結果が得られます。 その結果、現実世界でのそのアプリケーションも増加し、Tik Tok、Spotify、Zoom などの人気のあるアプリのモバイル アプリにプロセスが組み込まれています。
それでは、ASR について調べて、2022 年に最も人気のあるテクノロジの XNUMX つである理由を発見しましょう。
音声からテキストへの変換とは?
Speech to Text は、人間の音声をアナログからデジタル形式に変換する AI 強化テクノロジです。 さらに、収集されたデータのデジタル形式は、テキスト形式に転写されます。
テキストへの音声認識は、この方法とはまったく異なる音声認識と混同されることがよくあります。 音声認識では、人の声のパターンを識別することに重点が置かれますが、この方法では、システムは話されている言葉を識別しようとします。
Speech to Text の一般名
この高度な音声認識技術も人気があり、次の名前で呼ばれています。
- 自動音声認識 (ASR)
- 音声認識
- コンピュータ音声認識
- 音声文字変換
- スクリーンリーディング
自動音声認識の仕組みを理解する
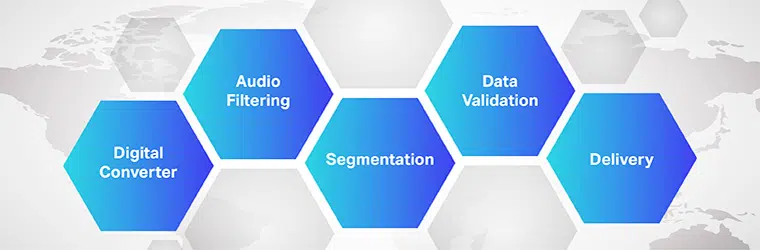
音声からテキストへの翻訳ソフトウェアの動作は複雑で、複数の手順を実行する必要があります。 ご存知のように、speech-to-text はオーディオ ファイルを編集可能なテキスト形式に変換するために設計された専用のソフトウェアです。 音声認識を活用してそれを行います。
プロセス
- 最初に、アナログ デジタル コンバーターを使用して、コンピューター プログラムが提供されたデータに言語アルゴリズムを適用し、振動と聴覚信号を区別します。
- 次に、関連する音は、音波を測定することによってフィルタリングされます。
- さらに、音は XNUMX 分の XNUMX または XNUMX 分の XNUMX 秒に分散/分割され、音素 (単語を別の単語と区別するための測定可能な音の単位) と照合されます。
- 音素は、既存のデータをよく知られている単語、文、および句と比較するために、数学モデルをさらに実行します。
- 出力は、テキストまたはコンピューターベースのオーディオ ファイルです。
[また読む: 自動音声認識の包括的な概要]

Speech to Text の用途は何ですか?
次のような複数の自動音声認識ソフトウェアの用途があります。
- コンテンツ検索: 私たちのほとんどは、電話で文字を入力することから、ソフトウェアが自分の声を認識して望ましい結果を提供するためにボタンを押すことに移行しました。
- カスタマーサービス: プロセスの最初のいくつかのステップを顧客に案内できるチャットボットと AI アシスタントが一般的になりました。
- リアルタイムクローズドキャプション: コンテンツへのグローバルなアクセスが増加するにつれて、リアルタイムのクローズド キャプションは著名かつ重要な市場となり、ASR の使用が促進されています。
- 電子文書: いくつかの管理部門は、文書化の目的を達成するために ASR の使用を開始し、速度と効率を向上させています。
音声認識の主な課題は何ですか?
音声注釈 まだ開発の頂点に達していません。 システムを効率的にするためにエンジニアが対処しようとしている多くの課題がまだあります。
- アクセントや方言をコントロールする。
- 話された文の文脈を理解する。
- 入力品質を増幅するためのバックグラウンド ノイズの分離。
- 効率的な処理のためにコードを別の言語に切り替えます。
- ビデオ ファイルの場合、スピーチで使用される視覚的な合図を分析します。
音声文字起こしと Speech-to-Text AI 開発
自動音声認識ソフトウェアの最大の課題は、出力を 100% 正確に作成することです。 生データは動的であり、単一のアルゴリズムを適用することはできないため、AI が適切なコンテキストでデータを理解できるようにトレーニングするために、データに注釈が付けられます。
このプロセスを実行するには、次のような特定のタスクを実装する必要があります。
 名前付きエンティティ認識 (NER): NER さまざまな名前付きエンティティを特定し、特定のカテゴリにセグメント化するプロセスです。
名前付きエンティティ認識 (NER): NER さまざまな名前付きエンティティを特定し、特定のカテゴリにセグメント化するプロセスです。- 感情とトピック分析: 複数のアルゴリズムを使用するソフトウェアは、提供されたデータのセンチメント分析を実行して、エラーのない結果を提供します。
 名前付きエンティティ認識 (NER):
名前付きエンティティ認識 (NER): - 意図と会話の分析: 意図検出は、話者の意図を認識するように AI をトレーニングすることを目的としています。 主に AI を利用したチャットボットの作成に使用されます。
まとめ
音声テキスト変換テクノロジーは現在、素晴らしい段階にあります。 アプリに音声検索および制御アシスタントを組み込むデジタルデバイスが増えるにつれ、音声文字起こしの需要が急増する見込みです。 この素晴らしい機能をアプリに追加したい場合は、Shaip の音声データ収集の専門家に問い合わせて詳細を確認してください。


