
自動音声認識システムと、Siri、Alexa、Cortana などの仮想アシスタントは、私たちの生活の一部となっています。 彼らが賢くなるにつれて、私たちの彼らへの依存度は大幅に高まっています。 明かりをつけることから、テレビ チャンネルを変更するために電話をかけることまで、私たちはこれらのスマート テクノロジーを活用してありふれたタスクを完了します。
しかし、これらの音声認識システムがどのように機能するのか疑問に思ったことはありませんか?
このブログでは、自動音声認識の基礎について説明します。 また、その動作と、Siri のような機能的な仮想アシスタントがどのように構築されているかについても説明します。
自動音声認識とは
自動音声認識 (ASR) は、複数の人工知能と機械学習アルゴリズムを活用して、コンピューター システムが人間の音声をテキストに変換できるようにするソフトウェアです。
与えられたコマンドを変換して分析した後、コンピューターはユーザーに適切な出力を返します。 ASR は 1962 年に初めて導入されて以来、継続的に運用を改善し、Alexa や Siri などの人気のあるアプリケーションにより大きな注目を集めてきました。
自動音声認識が Speech-to-Text Reader としても知られていることをご存知ですか? 詳しくはこちらのブログで!
ASR モデルをトレーニングするための音声収集のプロセスとは?
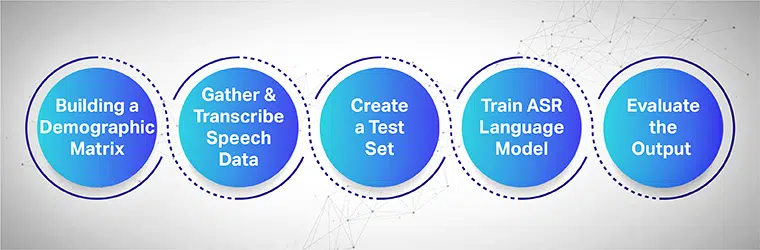
音声収集は、ASR モデルのフィードとトレーニングに利用される複数の領域からいくつかのサンプル録音を収集することを目的としています。 ASR システムは、音声とオーディオの大規模なデータセットが収集され、そのシステムに提供されるときに最高の効率を実現します。
シームレスに機能するには、収集された音声データセットに、ターゲットの人口統計、言語、アクセント、および方言がすべて含まれている必要があります。 次のプロセスは、複数のステップで機械学習モデルをトレーニングする方法を示しています。
人口統計マトリックスの構築から始めます
まず、場所、性別、言語、年齢、アクセントなど、さまざまな人口統計のデータを収集します。 また、通りの騒音、待合室の騒音、役所の騒音など、さまざまな環境騒音を確実に捉えてください。
音声データの収集と書き起こし
次のステップでは、さまざまな地理的位置に基づいて人間の音声と音声のサンプルを収集し、ASR モデルをトレーニングします。 これは重要なステップであり、人間の専門家が長い単語と短い単語を発話して、文の本物の感触をつかみ、異なるアクセントや方言で同じ文を繰り返す必要があります。
別のテスト セットを作成する
文字起こしされたテキストを収集したら、次のステップは、対応する音声データとペアリングすることです。 次に、データをさらにセグメント化し、それらから XNUMX つのステートメントを含めます。 これで、セグメント化されたデータ ペアから、さらにテストするためにセットからランダム データを取得できます。
ASR 言語モデルをトレーニングする
データセットに含まれる情報が多いほど、AI でトレーニングされたモデルのパフォーマンスが向上します。 したがって、以前に録音したテキストとスピーチの複数のバリエーションを生成します。 異なる音声表記法を使用して、同じ文を言い換えます。
出力を評価し、最後に反復する
最後に、ASR モデルの出力を測定してパフォーマンスを修正します。 モデルをテスト セットに対してテストして、その効率を判断します。 適切には、ASR モデルをフィードバック ループに関与させて、目的の出力を生成し、ギャップを修正します。
[また読む: 自動音声認識の包括的な概要]

音声認識のさまざまなユースケースとは?
今日、音声認識技術は多くの業界で広く普及しています。 この途方もない技術を使用しているいくつかの業界は次のとおりです。
 食品業界: Wendy's や McDonald's などの食品大手は、ASR を使用して顧客体験を強化しようとしています。 多くの店舗では、完全に機能する ASR モデルを展開して注文を受け、さらに調理セクションに渡して顧客の注文を準備しています。
食品業界: Wendy's や McDonald's などの食品大手は、ASR を使用して顧客体験を強化しようとしています。 多くの店舗では、完全に機能する ASR モデルを展開して注文を受け、さらに調理セクションに渡して顧客の注文を準備しています。- 電気通信: Vodafone は、世界最大の通信プロバイダーの XNUMX つです。 さまざまなクエリを解決し、通話を関係部門に再ルーティングするように導くASRモデルを活用して、カスタマーケアと電話リレーサービスを設計しました.
- 旅行と交通: Google Android Auto や Apple CarPlay が一般的になりました。 ほとんどの人は、ナビゲーション システムを起動したり、メッセージを送信したり、音楽プレイリストを切り替えたりするためにそれらを使用します。 しかし、技術の進歩に伴い、そのようなシステムはより洗練されてきています。
BMW 3 シリーズで導入された BMW インテリジェント パーソナル アシスタントは、通常の音声アシスタントよりもはるかにスマートです。 ドライバーは、車に関する情報を見つけたり、音声コマンドを使用して車を操作したりできます。 - メディアとエンターテイメント: メディア業界も、多くのプロジェクトで ASR を利用しています。 YouTube は、ライブの自動キャプションを生成する AI ベースのアシスタントを開始しました。 画面で話すと、アシスタントが字幕を提供して、より多くの Youtube ユーザーがビデオにアクセスできるようにします。
 食品業界: Wendy's や McDonald's などの食品大手は、ASR を使用して顧客体験を強化しようとしています。 多くの店舗では、完全に機能する ASR モデルを展開して注文を受け、さらに調理セクションに渡して顧客の注文を準備しています。
食品業界: Wendy's や McDonald's などの食品大手は、ASR を使用して顧客体験を強化しようとしています。 多くの店舗では、完全に機能する ASR モデルを展開して注文を受け、さらに調理セクションに渡して顧客の注文を準備しています。 電気通信: Vodafone は、世界最大の通信プロバイダーの XNUMX つです。 さまざまなクエリを解決し、通話を関係部門に再ルーティングするように導くASRモデルを活用して、カスタマーケアと電話リレーサービスを設計しました.
電気通信: Vodafone は、世界最大の通信プロバイダーの XNUMX つです。 さまざまなクエリを解決し、通話を関係部門に再ルーティングするように導くASRモデルを活用して、カスタマーケアと電話リレーサービスを設計しました. 旅行と交通: Google Android Auto や Apple CarPlay が一般的になりました。 ほとんどの人は、ナビゲーション システムを起動したり、メッセージを送信したり、音楽プレイリストを切り替えたりするためにそれらを使用します。 しかし、技術の進歩に伴い、そのようなシステムはより洗練されてきています。
旅行と交通: Google Android Auto や Apple CarPlay が一般的になりました。 ほとんどの人は、ナビゲーション システムを起動したり、メッセージを送信したり、音楽プレイリストを切り替えたりするためにそれらを使用します。 しかし、技術の進歩に伴い、そのようなシステムはより洗練されてきています。 メディアとエンターテイメント: メディア業界も、多くのプロジェクトで ASR を利用しています。 YouTube は、ライブの自動キャプションを生成する AI ベースのアシスタントを開始しました。 画面で話すと、アシスタントが字幕を提供して、より多くの Youtube ユーザーがビデオにアクセスできるようにします。
メディアとエンターテイメント: メディア業界も、多くのプロジェクトで ASR を利用しています。 YouTube は、ライブの自動キャプションを生成する AI ベースのアシスタントを開始しました。 画面で話すと、アシスタントが字幕を提供して、より多くの Youtube ユーザーがビデオにアクセスできるようにします。
[また読む: Speech-To-Text テクノロジーとは何ですか、またどのように機能しますか]
Shaipはどのように役立ちますか?
Shaip は、AI と ML の複数の分野で専門知識を持つ主要な AI トレーニング サービスの XNUMX つです。 これらは、さまざまなアプリケーションやプロジェクトに使用できる独自のデータ セットを構築するのに役立ちます。
Shaip が提供するサービスの一部は次のとおりです。
- 自動音声認識 (ASR)
- スクリプトスピーチコレクション
- トランスクリエーション
- 自発的スピーチコレクション
- 発話集・目覚まし言葉、
- テキスト読み上げ(TTS)
これらのサービスを利用すると、AI ベースのプロジェクトで最良の結果を得ることができます。 これらのサービスの詳細については、今すぐ当社の専門家チームにお問い合わせください。


